시작하기에 앞서
최근 Shopify Engineering Blog에 올라온 We replaced Redis with MySQL for inventory reservations—and it scaled 글을 읽었다.
제목만 보면 “Redis를 MySQL로 바꿨다” 정도로 보이지만, 실제 내용은 단순한 저장소 교체가 아니다. 커머스에서 가장 민감한 문제 중 하나인 재고 예약을 어떻게 정확하고 빠르게 처리할지에 대한 이야기다.
예약 모델을 Redis로 처리하면 빠르긴 한데, Redis와 MySQL 사이의 정합성은 어떻게 보장할까?
이 질문이 흥미로웠다. 나도 재고를 Redis에 담아 처리하는 구조를 보면서 비슷한 고민을 했기 때문이다.
재고 예약이 필요한 이유
커머스에서 재고 차감은 단순히 stock = stock - 1로 끝나지 않는다.
사용자가 결제하기 버튼을 누른 순간을 생각해보자. 이때 시스템은 아직 결제가 성공했는지 알 수 없다. PG 승인 과정이 남아 있고, 카드사 응답이 지연될 수도 있고, 사용자가 결제창에서 이탈할 수도 있다.
그렇다고 결제가 끝날 때까지 아무것도 하지 않으면 문제가 생긴다.
- A 사용자가 마지막 재고 1개를 결제 중이다.
- B 사용자도 같은 재고 1개를 결제 중이다.
- 둘 다 결제가 성공하면 마지막 재고가 두 번 팔린다.
이게 오버셀(oversell)이다.
반대로 너무 보수적으로 막아도 문제가 된다. 실제로는 재고가 있는데 품절이라고 판단하면 판매 기회를 잃는다. 그래서 재고 시스템은 두 가지를 동시에 만족해야 한다.
- 실제 재고보다 많이 팔지 않아야 한다.
- 팔 수 있는 재고를 불필요하게 막지 않아야 한다.
Shopify는 이 문제를 Reserve와 Claim으로 나눠서 본다.
Reserve: 결제 처리가 시작될 때 몇 분 동안 재고를 임시로 잡아 둔다.Claim: 결제가 성공하면 재고 원장에 최종 차감을 반영한다.Release: 결제가 실패하거나 만료되면 잡아 둔 재고를 다시 풀어준다.
즉, 결제 중인 재고와 실제 판매 완료된 재고를 구분한다.
Redis 방식의 장점과 한계
기존 Shopify 시스템은 Redis를 사용했다. Redis에서 상품별 재고 수량을 들고 있고, 예약할 때 DECR, 해제할 때 INCR하는 방식이다.
이 구조의 장점은 분명하다. Redis의 원자 연산은 빠르고, 동시 요청을 처리하기도 좋다. 이벤트 상품처럼 순간적으로 요청이 몰리는 상황에서는 MySQL row 하나를 업데이트하는 것보다 훨씬 유리하다.
문제는 Redis가 최종 재고 원장이 아니라는 점이다.
보통 커머스 시스템의 최종 재고 기록은 MySQL 같은 영속 저장소에 있다. 그러면 예약은 Redis에 있고, 최종 차감은 MySQL에 있는 구조가 된다.
결제 시작
-> Redis에서 재고 예약
-> PG 결제 진행
-> 결제 성공
-> MySQL 재고 원장 차감
-> Redis 예약 정리이 흐름에서 Redis와 MySQL 작업을 하나의 ACID 트랜잭션으로 묶을 수 없다.
예를 들어 Redis에서는 재고를 잡았는데 MySQL 반영이 실패할 수 있다. 반대로 MySQL에는 차감했는데 Redis 예약 정리가 실패할 수도 있다. 네트워크 장애, 프로세스 종료, 타임아웃, 재시도 중복 같은 상황까지 고려하면 두 저장소 사이의 상태가 어긋날 가능성은 항상 남는다.
물론 보정 배치, 멱등 키, 재처리 큐, 대사 작업으로 줄일 수는 있다. 하지만 구조적으로 “예약 상태”와 “재고 원장”이 서로 다른 시스템에 있다는 사실은 바뀌지 않는다.
Shopify가 MySQL로 옮기고 싶었던 이유도 여기 있다. 예약과 원장을 같은 데이터베이스 안에 두면, Reserve와 Claim 과정에서 필요한 상태 변경을 하나의 트랜잭션 경계 안으로 가져올 수 있다.
그렇다고 수량 row 하나로 돌아가면 안 된다
여기서 단순히 MySQL의 inventory.stock 컬럼만 업데이트하면 처음 문제로 돌아간다.
UPDATE inventory
SET stock = stock - 1
WHERE item_id = ?
AND stock >= 1;이 방식은 정확할 수는 있지만, 인기 상품 하나에 요청이 몰리면 같은 row에 대한 배타 락이 병목이 된다. 1,000명이 동시에 같은 상품을 사려고 하면 결국 한 줄로 선다.
Shopify의 핵심 아이디어는 수량 컬럼 하나가 아니라 판매 가능한 단위 하나를 row 하나로 표현하는 것이다.
예를 들어 어떤 상품의 특정 위치 재고를 예약할 수 있는 단위가 5개라면 다음처럼 본다.
reservation_units
item_id | location_id | unit_id
--------|-------------|--------
100 | 1 | 1
100 | 1 | 2
100 | 1 | 3
100 | 1 | 4
100 | 1 | 5사용자 A가 1개를 예약하면 이 중 한 row를 가져간다. 사용자 B가 동시에 들어오면 같은 row를 기다리는 대신 아직 잠기지 않은 다른 row를 가져가면 된다.
여기서 MySQL 8의 SKIP LOCKED가 중요해진다.
START TRANSACTION;
SELECT unit_id
FROM reservation_units
WHERE item_id = ?
AND location_id = ?
ORDER BY unit_id
LIMIT 1
FOR UPDATE SKIP LOCKED;
-- 선택한 unit을 예약 처리
COMMIT;FOR UPDATE는 선택한 row에 락을 건다. 그런데 SKIP LOCKED가 붙으면 이미 다른 트랜잭션이 잠근 row를 기다리지 않고 건너뛴다.
즉, 동시 요청들이 같은 재고 row 하나를 두고 줄 서는 대신, 서로 다른 unit row를 잡아갈 수 있다.
요청 A -> unit 1 lock
요청 B -> unit 1은 잠겨 있으니 skip, unit 2 lock
요청 C -> unit 1, 2는 skip, unit 3 lock재고를 숫자 하나로 볼 때는 stock row가 병목이었다. 재고를 여러 개의 예약 가능한 unit으로 펼치면 병목이 분산된다.
그런데 재고 1개당 row 1개를 사용하면 테이블 사이즈가 너무 커지지 않을까?
재고 1개당 row 1개로 관리하는 방식은 동시성 측면에서는 좋아 보인다. 하지만 현실적으로는 row 수가 너무 많이 늘어날 수 있다.
예를 들어 어떤 상품이 50,000개 있고, 여러 물류 위치에 흩어져 있다고 하자. 정말 전체 수량만큼 예약 unit row를 만들어두면 테이블 크기와 인덱스 크기가 빠르게 커진다. 재고 수량이 큰 상품일수록 예약 테이블이 비대해지고, 조회해야 하는 범위도 커질 수 있다.
그래서 나도 예전에 이 방식을 떠올렸지만 “재고 수량만큼 row를 만드는 것은 운영에서 부담이 크지 않을까?”라고 생각했다.
Shopify의 해결 방식이 인상적이었던 이유는 여기 있다. Shopify는 모든 재고를 unit row로 펼치지 않았다. 대신 bounded pool을 둔다.
쉽게 말하면 이렇다.
- 실제 재고의 최종 기준은 inventory ledger에 둔다.
- 예약 테이블에는 당장 예약 가능한 unit row만 일정 개수까지 유지한다.
- Shopify 글에서는 상품/위치 조합마다 최대 1,000개 수준으로 제한한다.
- 예약으로 pool이 줄어들면 replenishment 과정이 ledger를 보고 다시 채운다.
inventory ledger
- 실제 재고의 기준
- 최종 차감의 source of truth
reservation_units
- 예약 경합을 분산하기 위한 bounded pool
- 상품/위치별 최대 N개만 유지이렇게 하면 재고 1개당 row 1개의 장점을 가져가면서도, 전체 재고 수량만큼 row가 폭증하는 문제를 줄일 수 있다.
중요한 점은 reservation unit table이 전체 재고 원장이 아니라는 것이다. 이 테이블은 예약을 빠르게 분산 처리하기 위한 작업 공간에 가깝다. 원장은 따로 있고, pool은 원장 범위 안에서 유지된다.
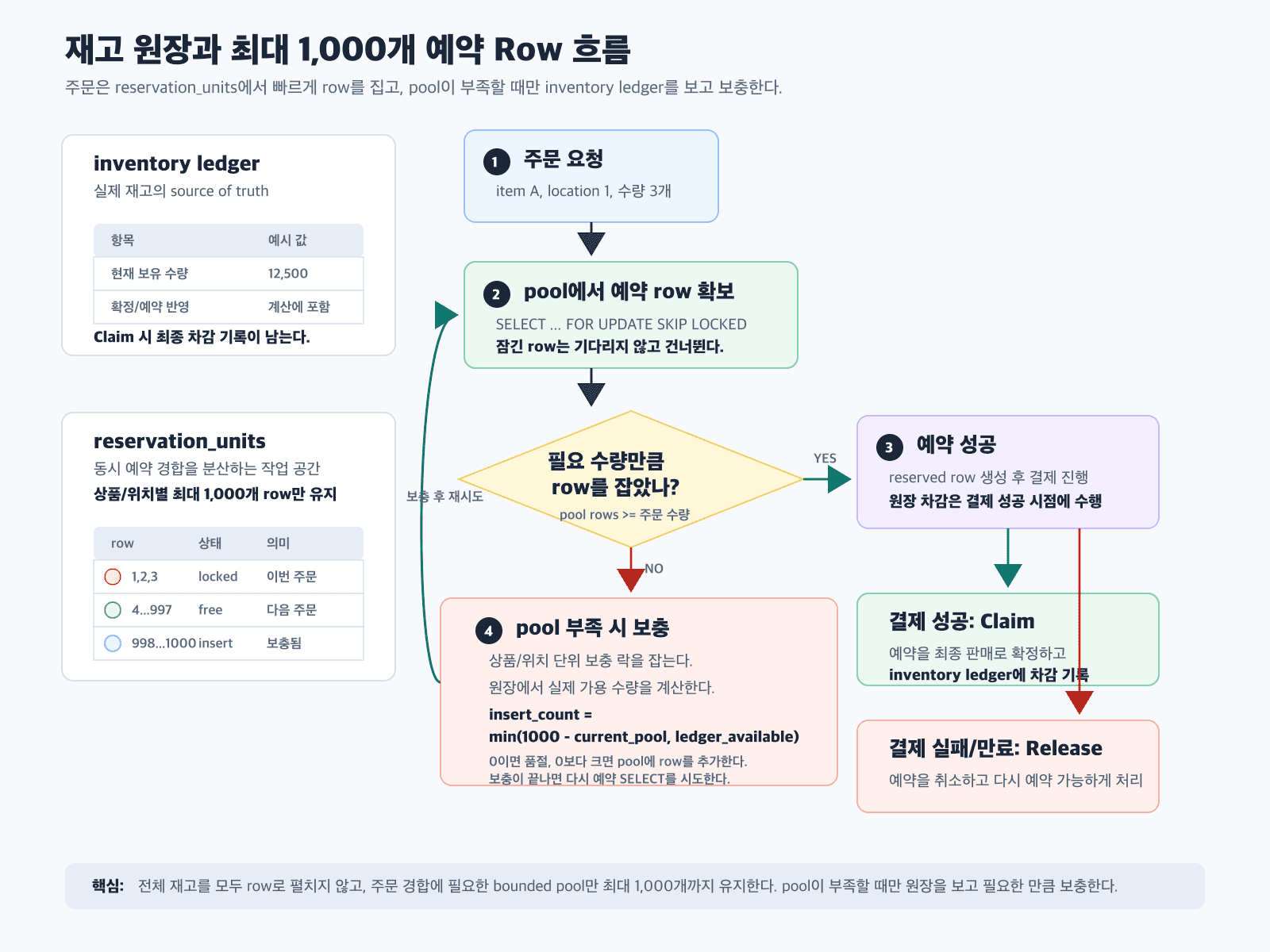
그림으로 보면 아래와 같다.
pool이 비면 어떻게 하나?
bounded pool을 쓰면 자연스럽게 다음 질문이 생긴다.
pool이 비었는데 실제 재고는 남아 있으면 어떻게 할까?
Shopify는 이때 보충(replenishment)을 수행한다. 예약 요청이 들어왔는데 pool이 부족하면, inventory ledger를 기준으로 예약 가능한 unit row를 다시 채운다.
주문이 들어왔을 때 흐름을 조금 더 구체적으로 풀면 이렇다.
- 주문 요청이 들어오면 먼저
reservation_units에서 주문 수량만큼 row를 잡는다. - 이때
SELECT ... FOR UPDATE SKIP LOCKED를 사용해 이미 다른 주문이 잡은 row는 기다리지 않고 건너뛴다. - 필요한 수량만큼 row를 잡았다면 예약을 성공시킨다.
- 필요한 수량보다 pool row가 부족하면 보충 트랜잭션을 시작한다.
- 보충 트랜잭션은 inventory ledger를 보고 실제로 예약 가능한 수량을 계산한다.
- 현재 pool row 수와 원장 기준 가용 수량을 비교해 필요한 만큼만
reservation_units에 row를 추가한다. - 보충이 끝나면 다시 예약 row 확보를 시도한다.
여기서 중요한 계산은 “무조건 1,000개를 insert한다”가 아니라는 점이다.
insert_count = min(1000 - current_pool_count, ledger_available)예를 들어 현재 pool에 997개 row가 남아 있고 원장 기준으로 예약 가능한 재고가 충분하다면 3개만 보충한다. 반대로 pool에 200개만 남아 있어도 원장 기준 가용 재고가 50개뿐이면 50개만 보충한다. 원장 기준 가용 재고가 0이면 보충하지 않고 품절로 처리해야 한다.
즉, reservation_units는 재고 자체가 아니다. 주문 경합을 빠르게 처리하기 위한 bounded pool이다. 실제로 얼마나 더 예약 가능한지는 inventory ledger가 결정한다.
다만 이 과정에서도 조심해야 한다. 여러 요청이 동시에 “pool이 비었다”고 판단해서 모두 insert를 시도하면 thundering herd가 된다. 그래서 같은 상품/위치에 대해서는 한 트랜잭션만 보충하도록 락을 잡고, 나머지 요청은 보충이 끝나기를 기다린다.
이 구조에는 지연 가능성이 있다.
예를 들어 어떤 사용자가 한 번에 1,000개를 구매하면 pool이 한 번에 비워질 수 있다. 그러면 다음 요청은 replenishment를 기다리느라 latency가 길어질 수 있다.
이 부분이 신경 쓰일 수 있다. 하지만 현실적으로 한 명이 특정 상품을 한 번에 1,000개 구매하는 경우가 자주 있는지 생각해보면, 대부분의 커머스에서는 감수 가능한 trade-off일 가능성이 높다.
설계는 항상 워크로드를 봐야 한다. Shopify도 1,000이라는 숫자를 이론적으로 정한 것이 아니라, flash sale 상황에서 관측한 상품/위치별 peak reservation rate를 기준으로 잡았다.
즉, 이 구조의 핵심은 “항상 1,000이면 된다”가 아니다.
핵심은 다음에 가깝다.
- 전체 재고를 모두 row로 펼치지 않는다.
- 동시 예약에 필요한 만큼의 작은 pool만 유지한다.
- pool 크기는 실제 트래픽과 보충 속도를 기준으로 잡는다.
- pool이 비는 예외 경로는 latency를 조금 쓰더라도 정확성을 유지한다.
정리
Shopify의 재고 예약 구조를 내 방식으로 요약하면 다음과 같다.
- Redis 예약과 MySQL 원장이 분리되어 있으면 원자성 문제가 남는다.
- MySQL로 합치면 ACID 트랜잭션 안에서 예약과 원장을 함께 다룰 수 있다.
- 하지만 수량 컬럼 하나를 업데이트하면 hot row 병목이 생긴다.
- 그래서 예약 가능한 단위를 row로 펼치고
SKIP LOCKED로 잠긴 row를 건너뛴다. - 전체 재고를 모두 펼치면 row가 폭증하므로 bounded pool을 유지한다.
- pool은 inventory ledger를 기준으로 보충한다.
- 복합 기본 키, 격리 수준, 락 순서, 배치 쿼리까지 맞춰야 실제로 동작한다.
- 마지막 병목은 쿼리가 아니라 checkout 전체의 connection 점유 시간일 수 있다.
이번 글에서 가장 크게 배운 것은 SKIP LOCKED 자체보다도 문제를 보는 관점이었다.
재고 시스템은 빠른 차감 로직 하나로 끝나지 않는다. 예약, 결제, 원장, 만료, 보정, connection, rollout까지 하나의 흐름으로 봐야 한다.
그리고 Redis를 쓸지 MySQL을 쓸지는 정답의 문제가 아니다. 중요한 것은 내가 어떤 불일치 가능성을 받아들이고 있는지, 그 불일치가 실제로 발생했을 때 어디까지 영향을 주는지, 그리고 그 비용을 줄이기 위해 어떤 구조를 선택할지다.
Shopify의 사례는 “기존 데이터베이스도 충분히 강력할 수 있다”는 이야기이기도 하지만, 더 정확히는 “데이터베이스를 제대로 이해하고 관찰하면 전용 인프라로만 풀 수 있다고 생각했던 문제도 다시 볼 수 있다”는 이야기라고 느꼈다.