
최근 NodeJS + Nestjs 환경의 프로젝트를 Kotlin + Spring boot 환경으로 컨버팅을 완료했다.
이렇게 기술스택 전환할 때 가장 중요한 것은 새 프레임워크에 맞게 다시 만드는 일이 아니라, 기존 서비스와 같은 동작을 끝까지 유지하는 일이다. 특히나 운영중인 서비스라면 더더욱.
이번 작업에서도 기준은 단순하고 명확했다. 기존 서버는 Node.js와 NestJS였고, 새 서버는 Kotlin과 Spring Boot였다.
하지만 성공 기준은 “Spring으로 잘 옮겼는가”가 아니라 “기존 NestJS 서버와 구분되지 않는가”였다.
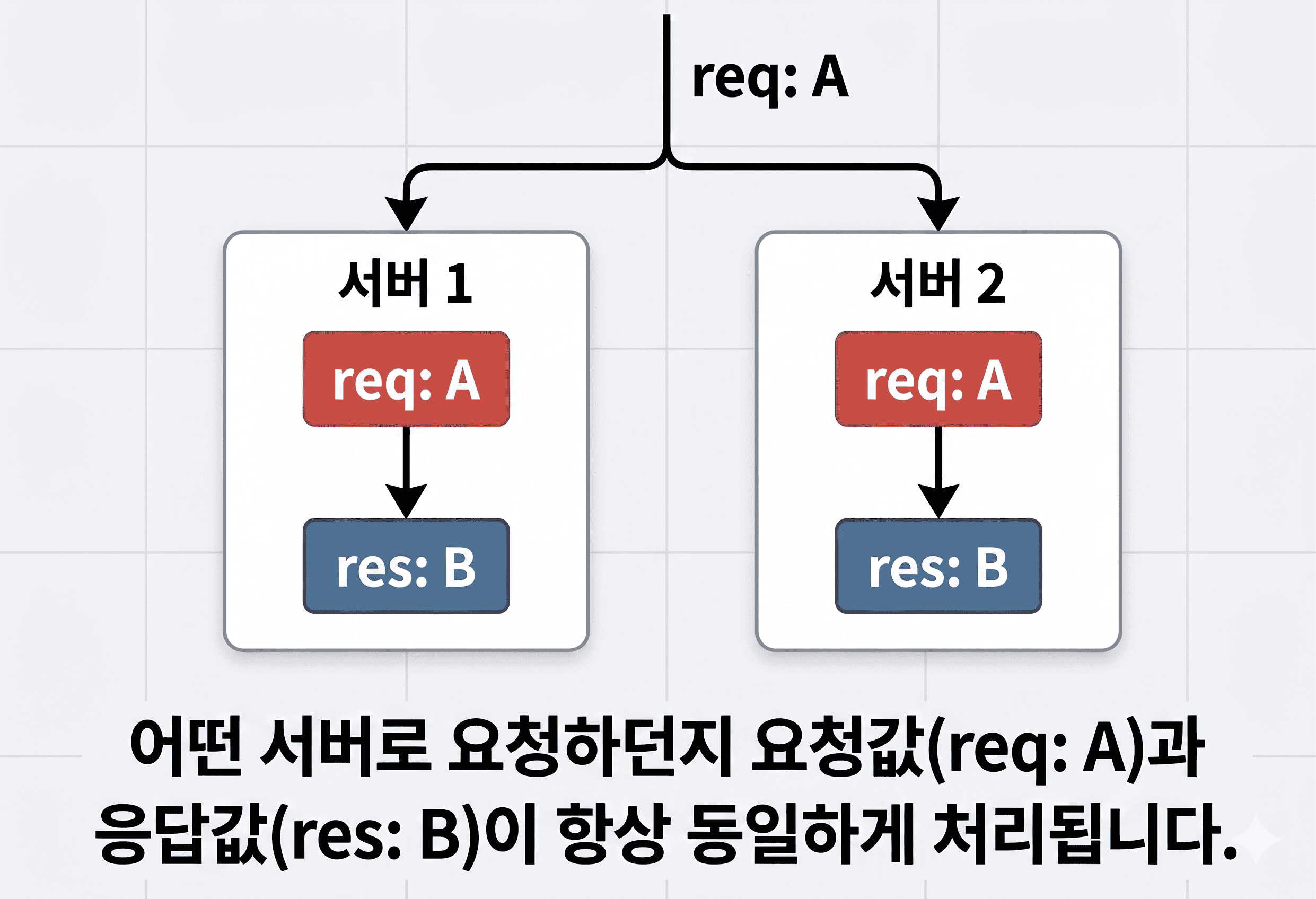
1. 기존 서버는 동작하는 상태에서 새로운 서버를 개발한다
기존 nestjs 서버는 그대로 운영되도록 두고, 별도의 spring 서버를 동일한 api를 하나씩 만들었다.
이 방식의 장점은 비교 기준이 항상 살아 있다는 점이다.
이렇게 해야 구현을 바꾸는 동안에도 기준점이 사라지지 않는다. 기술스택 전환은 기능 개발보다 교체 공학에 가깝기 때문이다.
단, 이 방식은 빠른 기간안에 끝내야 한다. 왜냐하면 기능의 추가나 수정이 필요한 경우 2개의 서버에 작업을 해야하는 단점이 있다.
2. 코드보다 계약을 먼저 맞췄다
실제로 맞춰야 했던 것은 클래스 구조나 코드 스타일이 아니었다. 먼저 본 것은 아래 계약들이었다.
- URL path
- request와 response 형식
- HTTP status
- 인증 실패 방식
- validation 에러 형태
- 데이터베이스 side effect

즉, 이번 전환에서 먼저 비교한 것은 내부 구현이 아니라 외부로 드러나는 계약과 실제 side effect였다.
새 구현이 더 예뻐 보여도, 이 계약들이 달라지면 교체는 실패한다. 그래서 이번 전환에서는 “더 좋은 구조”역시 중요하지만 무엇보다 중요한건 “같은 결과”였다.
3. parity test는 응답과 데이터베이스를 같이 봐야 한다
이번 작업에서 가장 중요한 것은 parity test였다. 응답만 같다고 해서 안전한 교체라고 볼 수는 없기 때문이다.
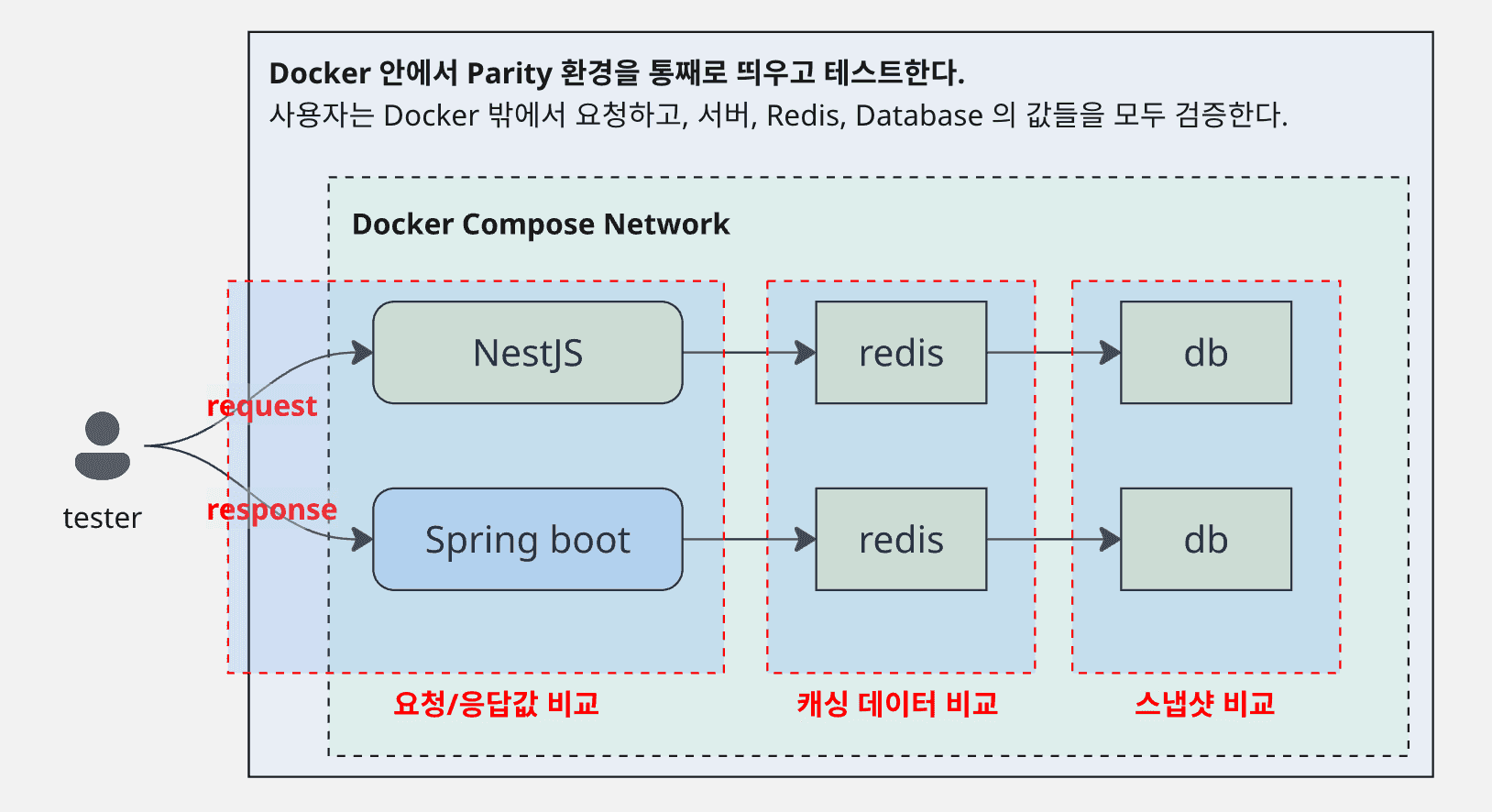
실행 환경도 한 번에 테스트 가능하도록 모두 Docker 환경에서 띄운단.
테스터의 api 요청에 대해 서버 각각으로 요청을 보내고 요청 -> redis -> db -> 응답값 전 구간의 스냅샷을 비교하는 형식이다.
즉, 응답만 비교한 것이 아니라 각 서버가 남긴 Redis 상태와 Database snapshot도 따로 읽어서 맞춘다.
이렇게 해야 인증 캐시, 세션성 데이터, 쓰기 결과까지 포함해서 정말 같은 동작인지 확인할 수 있다.
테스트 방식은 단순했다.
- nestjs 서버와 spring 서버를 동시에 띄운다
- 외부 연동은 공통 mock으로 고정한다
- 같은 요청을 두 서버에 보낸다
- HTTP 응답, Redis 상태, 데이터베이스 snapshot을 함께 비교한다
이렇게 해야 controller 차이, 인증 차이, cache 차이, persistence 차이를 빠르게 분리할 수 있다. 특히 Redis와 데이터베이스 쓰기 결과까지 비교해야 실제 운영 전환에서 늦게 터지는 회귀를 줄일 수 있다.
여기에 이번에는 AI hook도 같이 붙였다. AI가 controller, service, query, DTO를 수정하면 바로 parity harness가 다시 실행되도록 연결해 두었다. 그래서 사람이 매번 어떤 요청을 다시 돌려야 할지 판단하지 않아도, 변경 직후에 같은 요청 세트가 자동으로 두 서버에 다시 들어갔다.
중요한 점은 AI에게 단순히 코드만 작성하게 한 것이 아니라, 검증 루프 안에 넣었다는 것이다. 응답, Redis, DB snapshot 중 하나라도 어긋나면 mismatch report가 다시 쌓이고, 그 결과를 기준으로 AI가 다음 수정을 진행했다. 즉 구현과 검증이 분리된 것이 아니라, 수정 -> parity 실행 -> mismatch 수집 -> 재수정의 루프를 계속 돌리는 방식이었다.
4. 그러면 어떤 요청값을 비교할까
요청은 단순히 “성공하는 요청”만 비교해서는 안된다. 성공, 실패 그리고 그 요청/응답값 까지 모두 비교해야한다.
비교했던 요청 유형은 대략 아래와 같았다.
- 인증 헤더가 없는 요청
Bearer형식이 잘못된 요청- 만료되었거나 잘못 서명된 토큰
- 권한이 있는 사용자와 없는 사용자의 동일 요청
- 필수 필드가 빠진
POSTbody - enum, 날짜, 페이지네이션 값이 잘못된 query string
- 정상 등록, 수정, 조회, 목록 조회 요청
예를 들면 이런 식의 요청을 양쪽 서버에 똑같이 보냈다.
{
"method": "POST",
"path": "/api/brands",
"headers": {
"Authorization": "Bearer <token>"
},
"body": {
"name": "demo-brand",
"phone": "010-1111-1111",
"address": "서울특별시 송파구"
}
}조회 계열도 마찬가지였다.
GET /api/orders?page=1&size=20&status=completed
GET /api/invoices?from=2026-01-01&to=2026-01-31
GET /api/products?sort=latest핵심은 “URL만 같게 호출한다”가 아니었다. 같은 헤더, 같은 body, 같은 query string을 넣었을 때 두 서버가 같은 판정을 내리는지 보는 것이었다.
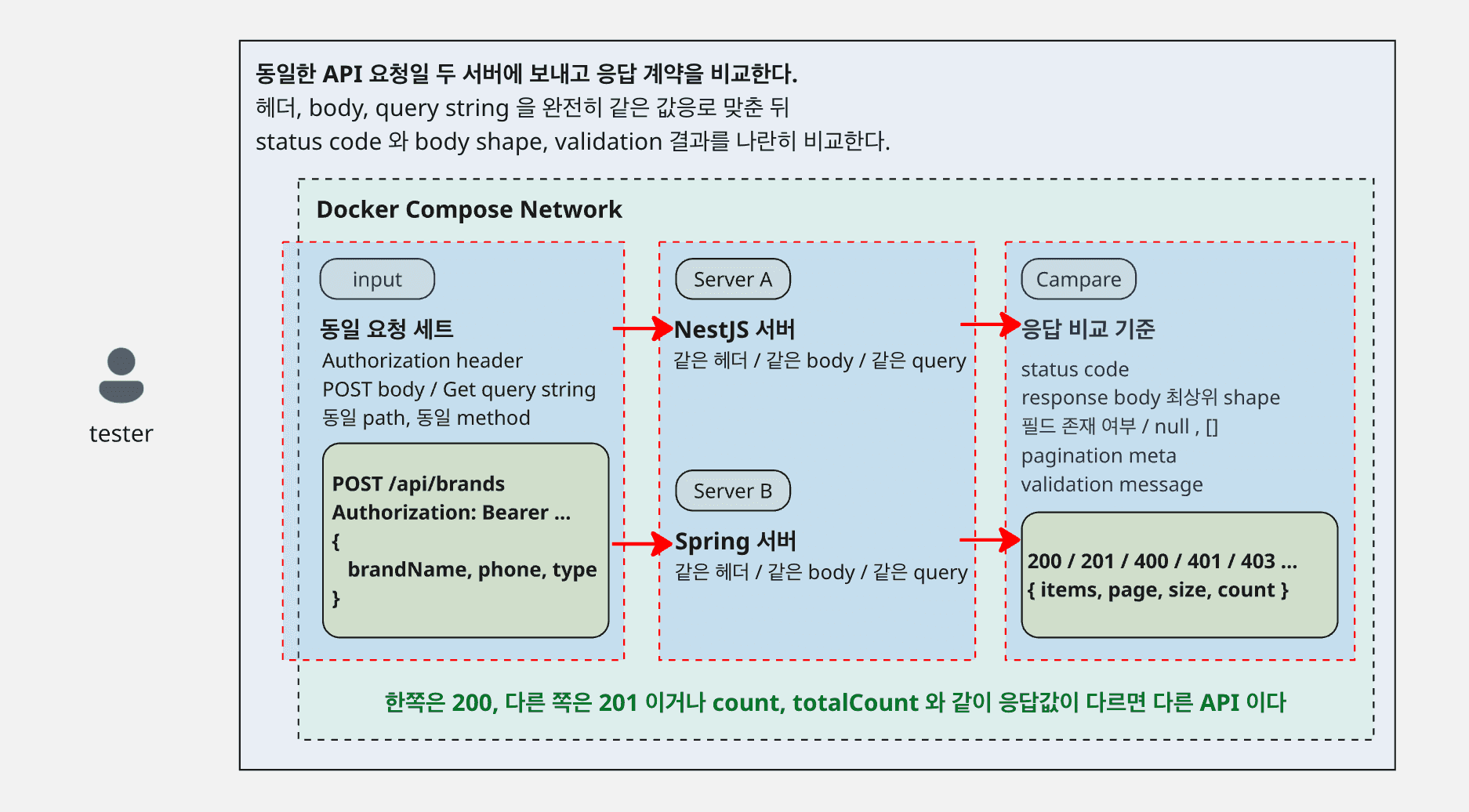
5. 어떤 응답값을 비교했는가
응답 비교도 body 문자열만 봐서는 안된다. 실제로는 아래 항목을 함께 맞췄다.
- HTTP status
- 응답 body의 최상위 구조
- 필드 존재 여부
null, 빈 배열, 빈 객체 차이- 리스트 정렬 순서
- 페이지네이션 메타 정보
- validation 에러 메시지 형태
- 인증 실패 시 에러 응답 형태
200과201같은 상태 코드 차이
예를 들어 목록 조회라면 이런 부분을 같이 봤다.
{
"items": [
{
"code": "BR-001",
"name": "demo-brand",
"status": "active"
}
],
"page": 1,
"size": 20,
"totalCount": 1
}여기서 중요한 것은 “필드가 비슷하다”가 아니라, 실제 클라이언트가 의존할 수 있는 shape가 완전히 같은지였다.
예를 들어 한쪽은 totalCount를 주고 다른 쪽은 count를 주거나, 한쪽은 빈 결과에서 []를 주고 다른 쪽은 null을 주면 실제로는 다른 API다.
실패 응답도 같은 방식으로 확인했다.
{
"statusCode": 401,
"message": "Unauthorized"
}또는 validation 오류라면
{
"statusCode": 400,
"message": [
"status must be a valid enum value",
"page must not be less than 1"
]
}같은 요청에 대해 이런 shape와 status가 동일해야만 실제 클라이언트 동작도 동일해진다.
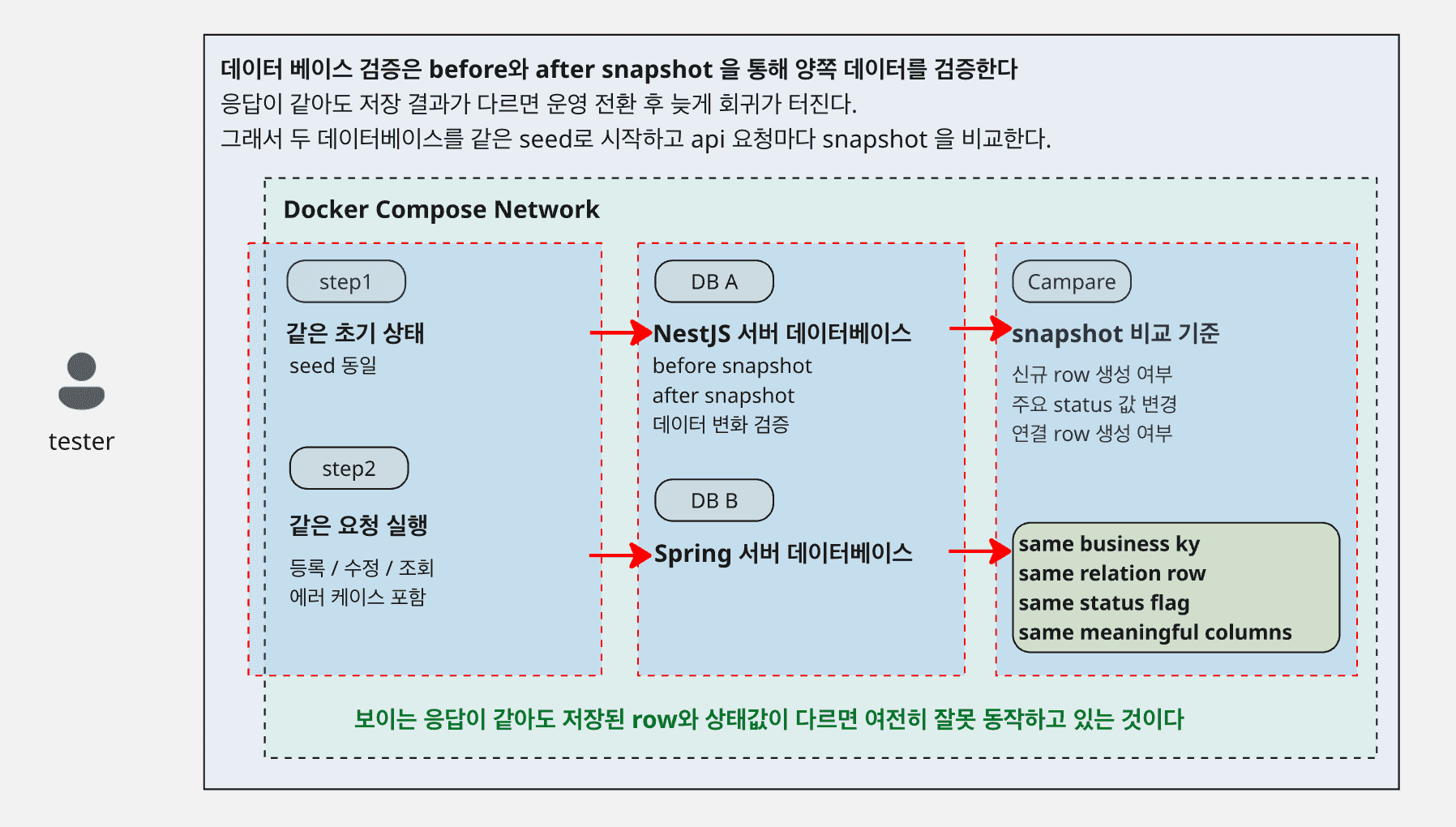
6. 데이터베이스 값은 어떻게 검증할 수 있을까
데이터베이스는 두 서버가 각자 분리된 인스턴스를 쓰도록 만들고, 테스트 시작 시점에는 항상 같은 seed 데이터로 맞췄다.
검증 순서는 다음과 같았다.
- 두 데이터베이스를 같은 초기 상태로 만든다
- 요청을 두 서버에 각각 보낸다
- 요청 전후 snapshot을 읽는다
- 변경된 row와 주요 컬럼을 비교한다
여기서 snapshot은 단순 dump가 아니라, 실제로 의미 있는 비즈니스 컬럼 위주로 정리해서 비교했다.
- 신규 row가 생성되었는가
- 기존 row의 상태 값이 바뀌었는가
- 연결 테이블의 관계 row가 같이 생겼는가
- 예상한 부가 설정 값이 저장되었는가
- soft delete 나 status flag가 동일하게 바뀌었는가
예를 들면 등록 요청 이후에는 아래 같은 관점으로 봤다.
before
- brand row 없음
- settlement row 없음
after
- brand row 1건 생성
- settlement row 1건 생성
- 두 row가 같은 business key로 연결
- status = pending수정 요청이라면 이런 식이다.
before
- status = pending
- displayName = old-name
after
- status = approved
- displayName = new-name이 과정에서 완전히 결정적이지 않은 값은 normalize했다.
- timestamp
- 정렬에 영향 없는 내부 순서
- presigned URL query string
- 런타임마다 달라질 수 있는 일부 생성 값
즉, “바이트 단위 완전 동일”이 아니라, 실제 비즈니스 결과가 같은지를 기준으로 비교했다.
7. mismatch를 줄여가며 마지막에만 전환했다
처음부터 모든 엔드포인트가 맞지는 않았다. 인증 판정, 상태 코드, 응답 body, 예외 흐름, 데이터베이스 쓰기 결과를 하나씩 맞춰 가면서 mismatch를 줄였다.
이 과정을 빠르게 반복하기 위해 AI 하네스 엔지니어링도 함께 했다. 핵심은 “AI가 수정한 뒤 사람이 수동으로 확인한다”가 아니라, “AI가 수정하면 hook이 하네스를 다시 돌리고, 통과 여부를 다시 AI가 받는다”는 구조를 만드는 것이었다. 요청 생성, 두 서버 호출, 결과 normalize, diff 출력, 실패 리포트 정리를 자동화해 두니 어느 부분이 아직 parity를 깨고 있는지 바로 드러났다.
결국 AI는 코드를 한 번에 완성하는 도구라기보다, mismatch를 줄여 가는 반복 작업을 계속 수행하는 작업자로 쓰였다. 그리고 그 작업자가 흔들리지 않게 만드는 장치가 바로 하네스였다. 테스트가 통과할 때까지 같은 기준으로 계속 검증하니, 사람이 중간마다 감으로 판단하는 구간이 많이 줄어들었다.
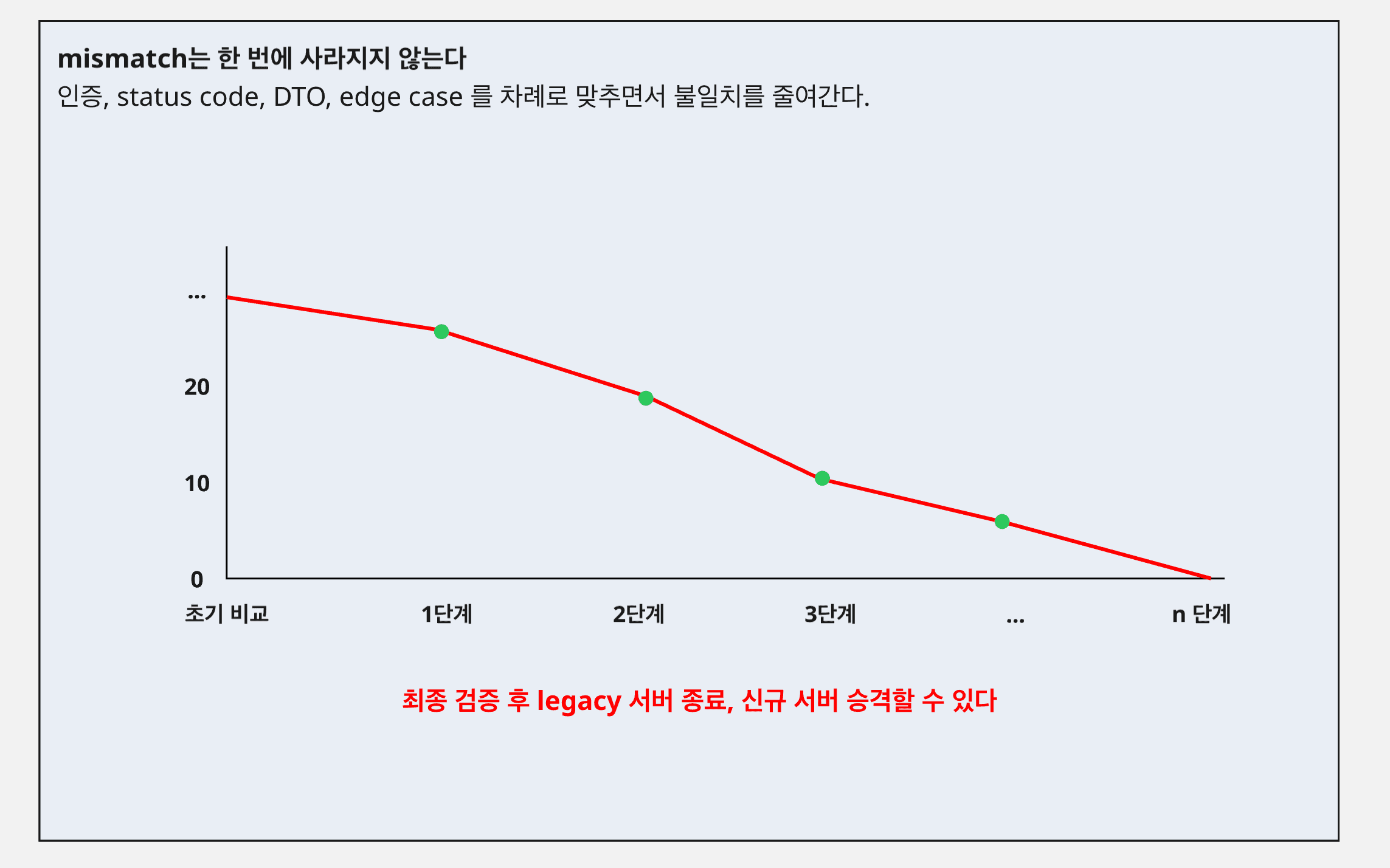
결국 마지막까지 확인한 것은 한 가지였다. 새 spring 서버가 기존 nestjs 서버와 같은 요청에 같은 결과를 주는가였다. 그 기준을 통과한 뒤에만 이름과 경로를 정리하고 최종 cutover를 진행했다.
마무리
과거 (최소 1~2년 이전에는) 운영중인 서비스의 기술스택 전환은 매우 많은 비용이 들어갔다. 전환 자체도 그렇지만, 테스트가 매우 어려웠다. 그래서 실제 운영단계 에서 2개의 서비스를 띄워두고 사용자의 요청값에 대해 뒷단에서 새로운 서버에도 요청을 보내서 같은 응답을 주는지 검증하기도 했다.
이번에는 이 비용 구조가 많이 달라졌다. AI가 코드를 작성하고, hook이 parity harness를 자동 실행하고, 실패한 mismatch를 다시 AI가 받아 수정하는 흐름을 만들 수 있었기 때문이다. 예전처럼 사람이 테스트 시나리오를 손으로 고르고, 결과를 읽고, 다시 수정 포인트를 정리하는 시간을 크게 줄일 수 있었다.
즉 이번 전환에서 AI의 역할은 “코드 생성기”에만 머물지 않았다. 하네스 엔지니어링을 통해 통과 기준을 먼저 고정하고, 그 기준을 만족할 때까지 자동으로 검증을 반복하는 구조를 만든 것이 더 중요했다. 운영 전환에서 진짜 가치가 있었던 것은 빠른 생성보다 빠른 검증이었다.
과연 이번에는 이 많은 코드 작업을 어떻게 했을까?
당연히 처음부터 끝까지 AI 가 해결했다. 나는 프로젝트 설계만 했다.
다음 글에서는 AI 를 어떻게 다뤄서 이걸 해냈는지 정리해보려고 한다.
- 기술스택 전환은 구현 프로젝트가 아니라 교체 프로젝트다
- 테스트 전략은 구현보다 먼저 있어야 한다
- cutover는 parity가 끝난 뒤에만 해야 한다
새 기술로 얼마나 빨리 다시 만들 수 있는가보다, 기존 서비스와 동일하다는 것을 어떻게 증명할 것인가를 먼저 설계하는 편이 훨씬 안전하다.