
한 줄 요약
TypeORM에서 MySQL을 사용할 때 연결 관리 방식은 TypeOrmModule을 쓰는지, 직접 new DataSource()를 쓰는지로 갈리지 않는다.
핵심은 DataSourceOptions 안에 replication 옵션이 있는지 여부다.
replication없음:mysql.createPool(...)경로replication있음:mysql.createPoolCluster(...)경로
즉, TypeOrmModule을 사용하더라도 내부적으로는 TypeORM DataSource를 만들고, 그 DataSourceOptions에 replication이 있으면 PoolCluster 방식으로 연결을 관리한다.
MySQL 장애 후 pool 복구 방식을 일반 pool처럼 단순하게 가져가고 싶다면, TypeORM의 replication 옵션을 쓰기보다 READ/WRITE DataSource를 명시적으로 분리하는 편이 낫다.
왜 이 차이가 중요할까
NestJS에서 TypeORM을 사용할 때 reader/writer를 나누기 위해 흔히 replication 설정을 고려한다.
new DataSource({
type: 'mysql',
replication: {
master: {
host: 'writer-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
},
slaves: [
{
host: 'reader-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
},
],
},
});이 구조의 장점은 분명하다. TypeORM이 query 목적에 따라 master와 slave를 내부에서 나눠준다.
하지만 MySQL driver 관점에서는 단순히 read/write routing만 생기는 것이 아니다. 연결 관리 방식이 일반 Pool에서 PoolCluster로 바뀐다. 그리고 이 차이는 MySQL이 죽었다가 다시 살아났을 때 체감 차이로 이어질 수 있다.
전체 구조
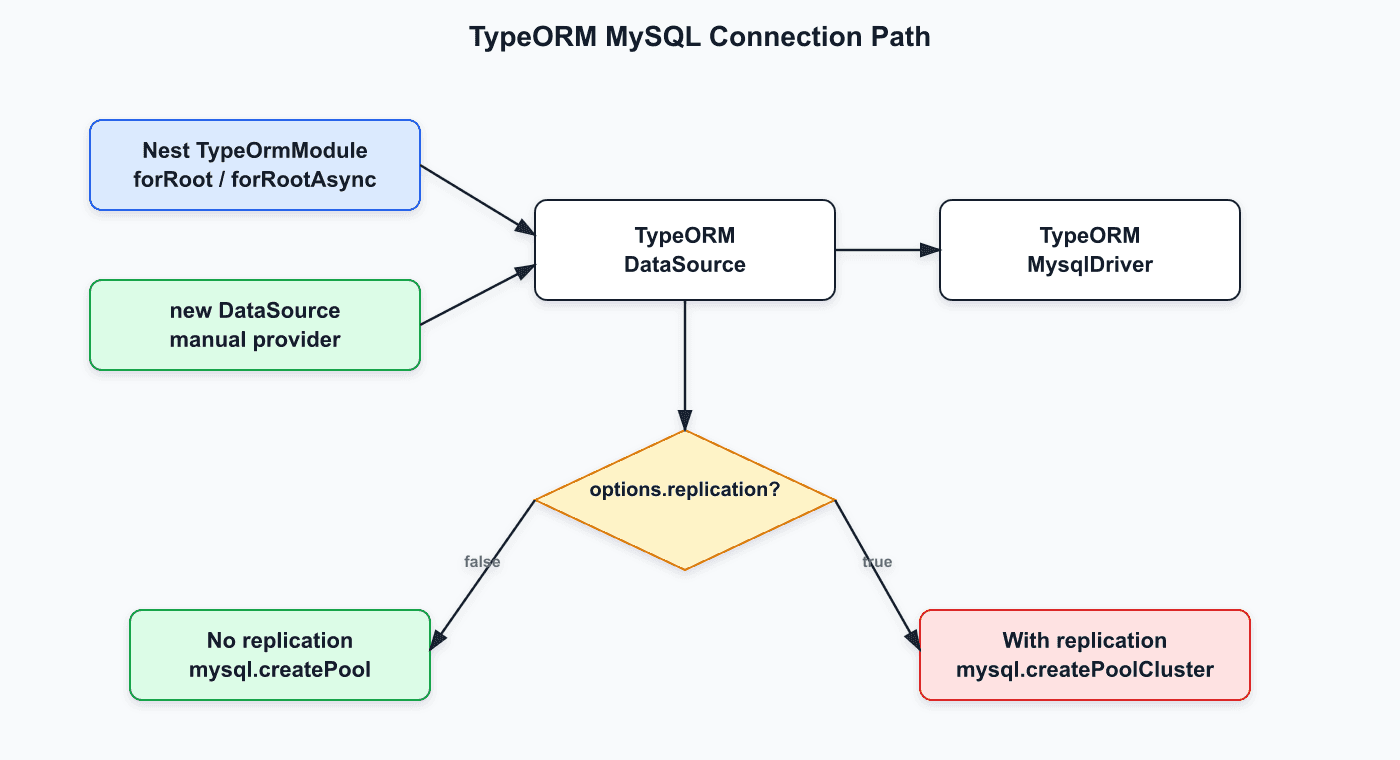
이 그림에서 중요한 점은 TypeOrmModule.forRoot()와 직접 만든 new DataSource()가 결국 같은 TypeORM DataSource로 들어간다는 것이다.
연결 관리 방식은 다음 기준으로 결정된다.
DataSourceOptions.replication 없음 -> createPool
DataSourceOptions.replication 있음 -> createPoolCluster따라서 문제를 볼 때 TypeOrmModule이냐 new DataSource()냐로 나누면 원인을 잘못 볼 수 있다. 실제 분기점은 replication 옵션이다.
연결 방식 1. replication 없음
replication 옵션이 없으면 TypeORM MySQL driver는 단일 DB endpoint에 대한 일반 pool을 만든다.
new DataSource({
type: 'mysql',
host: 'writer-or-reader-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
});이 방식은 하나의 endpoint를 대상으로 createPool을 사용하는 구조다.
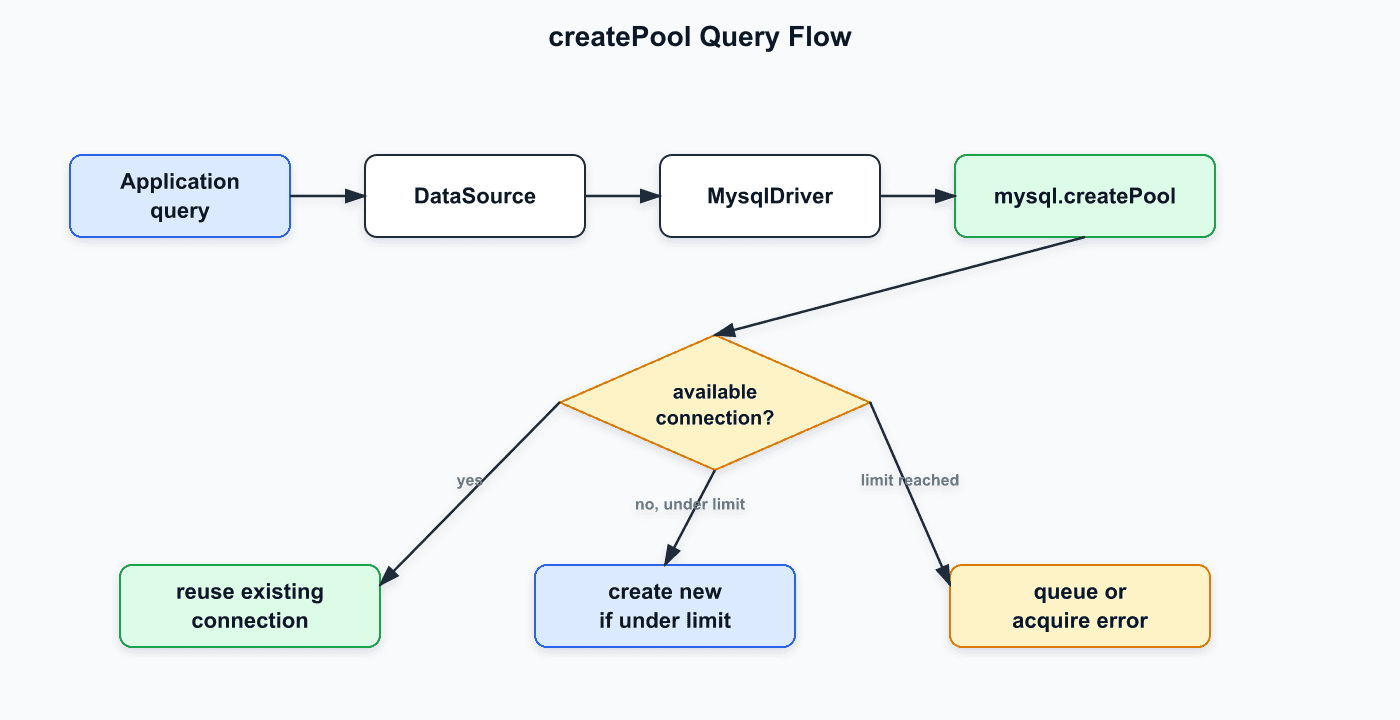
일반 pool은 connection을 필요한 만큼 lazy하게 만든다. connectionLimit이 100이어도 동시에 5개만 쓰면 실제 connection은 5개만 만들어진다.
그리고 query가 실행될 때는 대략 다음 흐름을 탄다.
pool.getConnection()
-> connection.query()
-> connection.release()pool.query(...)는 이 흐름을 줄여서 제공하는 API에 가깝다.
createPool의 장애 후 복구 흐름
일반 pool에서 중요한 특징은 장애를 connection 단위로 다룬다는 점이다.
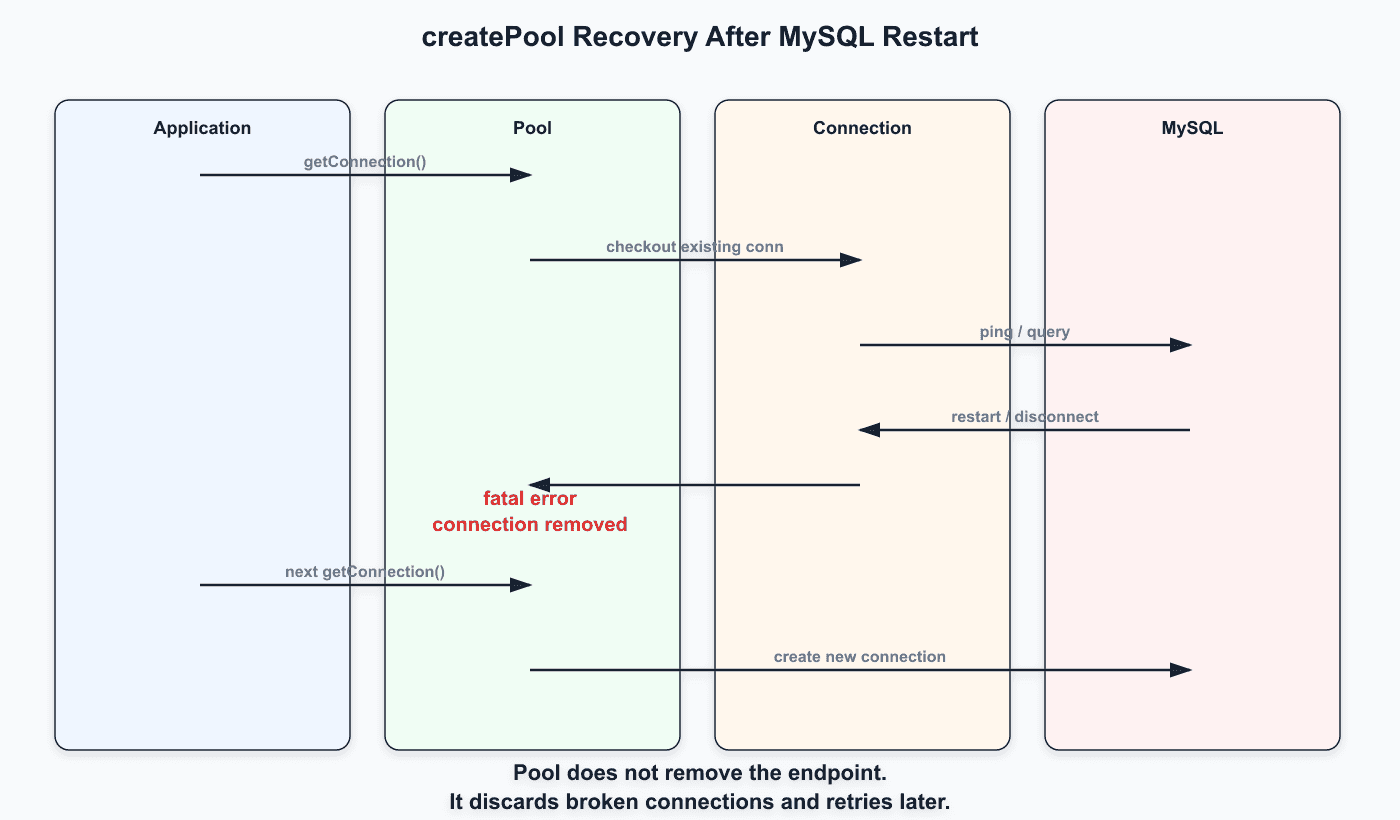
DB restart나 네트워크 문제로 기존 connection이 끊기면 해당 connection은 pool에서 제거된다.
이후 다음 getConnection() 시점에 pool에 빈 자리가 있으면 새 connection 생성을 다시 시도한다. 즉, 일반 pool은 “끊어진 connection 객체를 되살리는” 방식이 아니다. 끊어진 connection을 버리고, 다음 요청에서 같은 endpoint로 새 connection을 만드는 방식에 가깝다.
그래서 DB가 다시 살아난 뒤에는 다음 connection 생성 시점에 자연스럽게 복구될 가능성이 높다.
연결 방식 2. replication 있음
replication 옵션이 있으면 TypeORM MySQL driver는 일반 pool 하나가 아니라 PoolCluster를 만든다.
new DataSource({
type: 'mysql',
replication: {
master: {
host: 'writer-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
},
slaves: [
{
host: 'reader-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
},
],
},
});TypeORM은 replication.master를 MASTER node로 등록하고, replication.slaves를 SLAVE0, SLAVE1 같은 node로 등록한다.
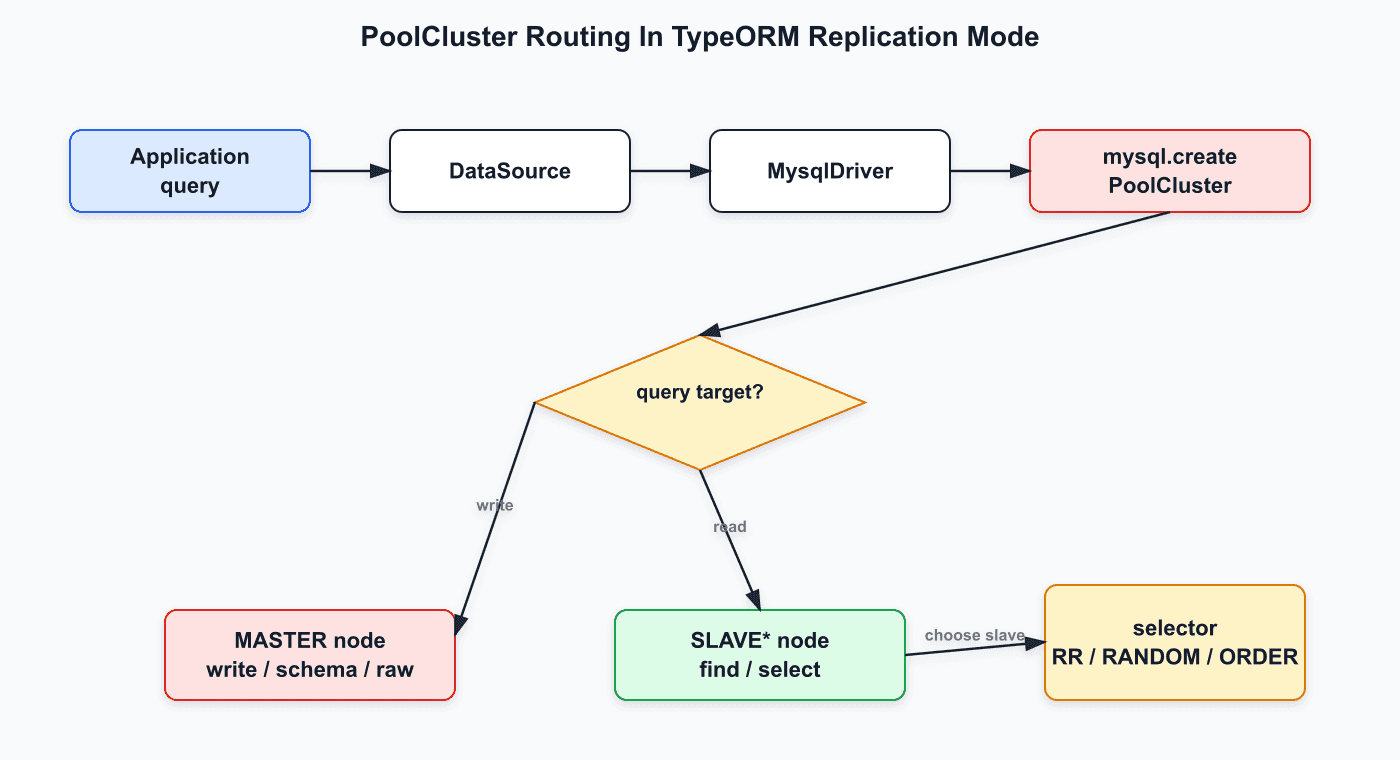
이 구조에서는 connection 요청이 곧바로 pool로 가지 않는다. 먼저 어떤 node를 쓸지 선택하고, 그 node의 pool에서 connection을 가져온다.
대표적으로 다음과 같은 선택이 일어난다.
- write, schema 관련 query:
MASTER - select 계열 query:
SLAVE* - slave가 여러 개면 selector 기준으로 선택
selector는 보통 다음 중 하나다.
RR: Round-RobinRANDOM: 무작위 선택ORDER: 순서상 먼저 사용 가능한 node 선택
PoolCluster의 장애 후 복구 흐름
PoolCluster는 일반 pool과 다르게 node 상태를 관리한다.
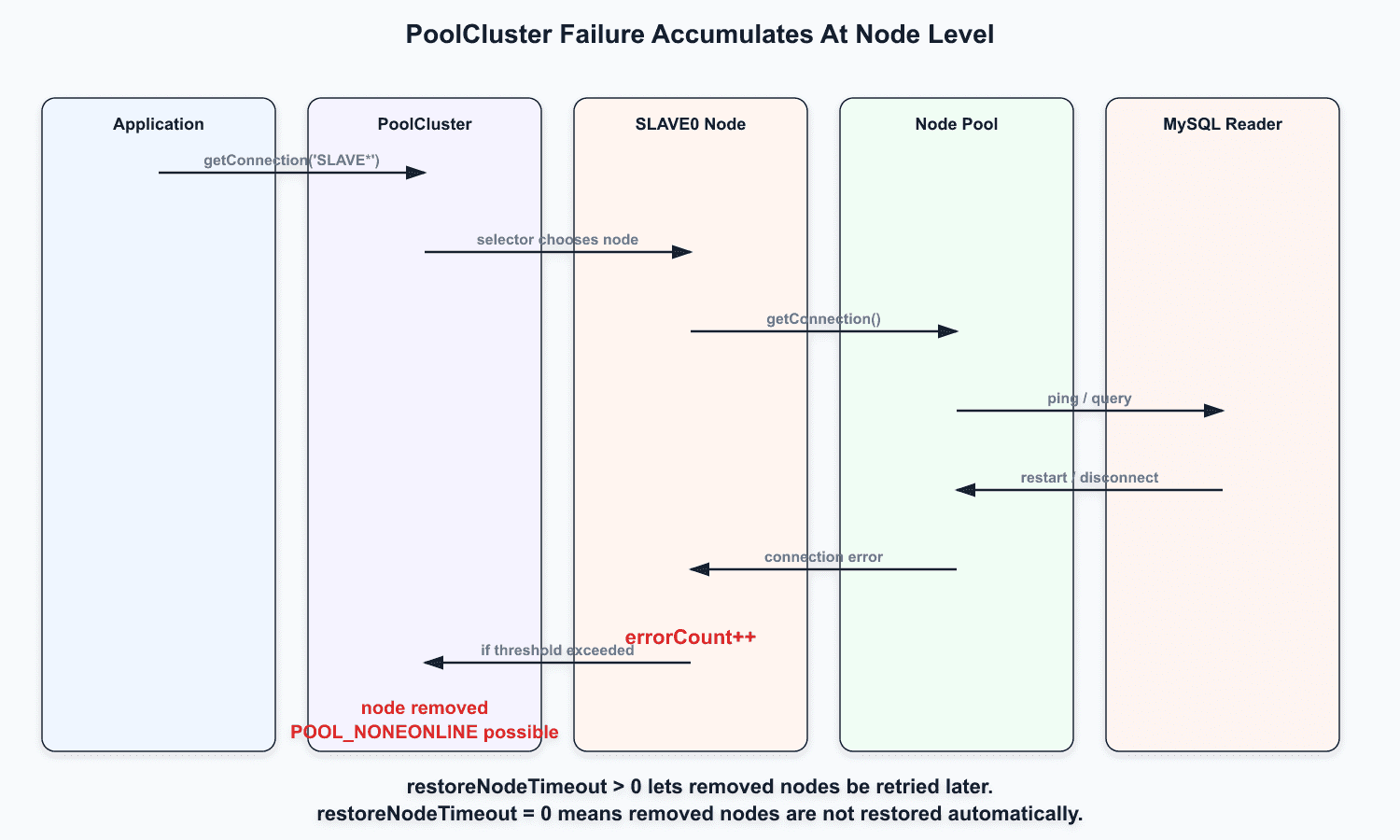
PoolCluster에는 일반 pool에는 없는 설정들이 있다.
| 설정 | 의미 | 기본값 |
|---|---|---|
canRetry |
connection 실패 시 재시도할지 결정 | true |
removeNodeErrorCount |
node 실패 횟수가 이 값을 넘으면 cluster에서 제거 | 5 |
restoreNodeTimeout |
제거된 node를 얼마 뒤 다시 복구 후보로 볼지 결정 | 0 |
selector |
여러 node 중 어떤 node를 고를지 결정 | RR |
여기서 운영상 특히 중요한 값은 restoreNodeTimeout이다.
restoreNodeTimeout이 0이면 실패 횟수 초과로 제거된 node는 자동으로 다시 사용되지 않을 수 있다. 즉, MySQL이 다시 살아났더라도 애플리케이션 프로세스 안의 PoolCluster는 해당 node를 다시 쓰지 못하는 상태가 될 수 있다.
반대로 restoreNodeTimeout을 0보다 크게 설정하면 제거된 node를 일정 시간 뒤 복구 후보로 되돌리고, 다음 connection 요청에서 재연결을 시도할 수 있다.
다만 이 방식은 “PoolCluster를 계속 사용할 때의 완화책”에 가깝다. 장애 후 복구 시점이 node 상태 관리 설정에 의존하게 되기 때문이다.
createPool과 PoolCluster의 핵심 차이
| 항목 | createPool | PoolCluster |
|---|---|---|
| 생성 조건 | replication 없음 |
replication 있음 |
| 관리 단위 | 하나의 DB endpoint에 대한 connection pool | 여러 DB endpoint를 node로 묶은 cluster |
| 장애 인식 | connection 단위 | node 단위 + connection 단위 |
| 실패 누적 | node error count 개념 없음 | node별 errorCount 누적 |
| 실패한 대상 처리 | 끊어진 connection 제거 후 다음 요청에서 새 connection 생성 | error count가 threshold를 넘으면 node 제거 |
| 복구 방식 | 다음 getConnection()에서 새 connection 생성 시도 |
restoreNodeTimeout 설정에 따라 제거 node 재시도 여부 결정 |
| routing | 애플리케이션이 어떤 DataSource를 쓰는지로 결정 | TypeORM replication mode와 query 종류에 따라 master/slave 선택 |
| read/write 분리 위치 | 애플리케이션 코드 또는 DI token | TypeORM replication 내부 |
일반 pool은 실패한 connection을 버리고 다음 요청에서 같은 endpoint로 새 connection 생성을 시도한다.
반면 PoolCluster는 실패를 node 상태로 누적한다. 실패가 반복되면 node가 cluster에서 제거될 수 있고, 제거된 node가 다시 복구 후보가 되는지는 restoreNodeTimeout 같은 설정에 좌우된다.
그래서 “MySQL이 죽었다가 다시 살아났는데 애플리케이션이 다시 붙지 못한다”는 현상은 일반 pool보다 PoolCluster에서 더 구조적으로 설명되기 쉽다.
해결 방향
목표가 PoolCluster의 node 제거/복구 동작을 피하는 것이라면 TypeORM의 replication 옵션을 사용하지 않는 것이 가장 단순하다.
대신 READ와 WRITE를 각각 독립적인 DataSource로 만든다.
const ReadDataSource = new DataSource({
type: 'mysql',
host: 'reader-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
});
const WriteDataSource = new DataSource({
type: 'mysql',
host: 'writer-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
});NestJS를 사용한다면 직접 provider를 만들어도 되고, TypeOrmModule.forRootAsync()를 사용해도 된다.
중요한 것은 둘 다 replication 옵션을 넣지 않는 것이다.
TypeOrmModule.forRootAsync({
name: 'READ_DB',
useFactory: async () => ({
type: 'mysql',
host: 'reader-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
}),
});
TypeOrmModule.forRootAsync({
name: 'WRITE_DB',
useFactory: async () => ({
type: 'mysql',
host: 'writer-host',
port: 3306,
username: 'user',
password: 'password',
database: 'database',
}),
});이 구조에서는 READ DataSource와 WRITE DataSource가 각각 일반 createPool 경로를 사용한다.
read/write 선택은 TypeORM replication 내부 routing이 아니라 애플리케이션 코드의 DataSource 또는 repository 선택으로 이동한다.
운영 기준
TypeORM 0.3 이후의 기본 연결 모델은 DataSource다. reader/writer를 운영해야 한다면 replication 옵션으로 하나의 DataSource 안에 묶는 방식보다, READ DataSource와 WRITE DataSource를 명시적으로 분리하는 방식이 더 예측 가능하다.
권장 기준은 다음과 같다.
replication옵션은 사용하지 않는다.- READ 전용 DataSource와 WRITE 전용 DataSource를 각각 만든다.
- 각 DataSource가 독립적인
createPool경로를 사용하게 한다. - read/write 선택은 TypeORM replication routing에 맡기지 않고, 애플리케이션의 DataSource 또는 repository 주입에서 명시한다.
- transaction, read-after-write, raw query는 WRITE DataSource를 사용하도록 기준을 세운다.
물론 PoolCluster를 반드시 써야 하는 상황도 있을 수 있다. 이 경우에는 removeNodeErrorCount, restoreNodeTimeout, canRetry, selector를 운영 의도에 맞게 명시해야 한다.
하지만 MySQL 장애 후 connection 복구 방식을 단순화하고 read/write 목적지를 명확하게 만들고 싶다면, replication 설정을 제거하고 DataSource를 명시적으로 분리하는 쪽이 더 낫다.
한 줄 결론
TypeORM에서 MySQL replication은 단순한 read/write routing 옵션처럼 보이지만, 실제로는 연결 관리 방식을 PoolCluster 경로로 바꾼다.
장애 후 복구 동작을 일반 pool처럼 단순하게 예측하고 싶다면 replication을 쓰지 말고 READ/WRITE DataSource를 분리하는 것이 좋다.
출처
- TypeORM DataSource 문서: https://typeorm.io/docs/data-source/data-source/
- TypeORM Multiple data sources and replication 문서: https://typeorm.io/docs/data-source/multiple-data-sources/
- NestJS Database 문서: https://docs.nestjs.com/techniques/database
- NestJS TypeORM source: https://raw.githubusercontent.com/nestjs/typeorm/11.0.0/lib/typeorm-core.module.ts
- TypeORM MySQL driver source: https://raw.githubusercontent.com/typeorm/typeorm/0.3.28/src/driver/mysql/MysqlDriver.ts
- mysqljs/mysql Pooling connections: https://github.com/mysqljs/mysql#pooling-connections
- mysqljs/mysql PoolCluster: https://github.com/mysqljs/mysql#poolcluster
- mysqljs/mysql Server disconnects: https://github.com/mysqljs/mysql#server-disconnects