시작하며
많은 제품팀이 기능을 출시할 때 이런 말을 한다.
이 버튼 색이 더 잘 될 것 같다.
문제는 제품에서 중요한 의사결정을 감으로만 하면, 실제로는 잘못된 결정을 꽤 자주 내린다는 점이다.
특히 전환율, 클릭률, 결제율, 재방문율 같은 지표는 작은 UI 변경에도 움직이지만, 그 변화가 정말 기능 때문인지 아니면 우연인지 구분하기는 생각보다 어렵다.
그래서 A/B Test 가 필요하다.
이번 글에서는 아래 내용을 실무 관점으로 정리해보려고 한다.
- A/B Test 가 필요한 이유
- A/B Test 에서 두 그룹으로 안정적으로 분배하는 방법
- 데이터는 어떻게 분석해야 하는가
1. A/B Test 가 필요한 이유
A/B Test 의 목적은 단순히 A 와 B 중 무엇이 더 좋아 보이는지 를 맞추는 것이 아니다.
핵심은 변경이 실제로 만들어낸 인과 효과 를 확인하는 데 있다.
직관은 자주 틀린다
제품을 오래 다룬 사람의 직감은 분명 가치가 있다.
하지만 직감은 어디까지나 가설이다.
- 눈에 더 잘 띄는 UI 가 실제 구매 전환으로 이어지지 않을 수 있다
- 클릭률이 올랐는데 결제율은 오히려 떨어질 수 있다
- 신규 사용자에게는 좋은 변화가 기존 사용자에게는 불편할 수 있다
즉, 좋아 보인다 와 실제로 좋다 는 다르다.
변화의 비용을 숫자로 설명할 수 있다
A/B Test 는 단순히 승패를 가르는 도구가 아니다.
변화의 크기를 설명하는 도구이기도 하다.
예를 들어, 어떤 개선안이 결제 전환율을 0.2%p 올렸다면 트래픽이 큰 서비스에서는 그 차이가 월 매출에도 차이를 만들 수 있다.
반대로 효과가 거의 없었다면 개발과 운영 복잡도를 늘리는 기능을 과감히 접을 수도 있다.
부작용을 함께 볼 수 있다
좋은 실험은 하나의 핵심 지표만 보지 않는다.
예를 들어 CTA 버튼을 더 강하게 노출해서 클릭률은 올랐다고 하자.
그런데 다음과 같은 부작용이 생길 수 있다.
- 상세 페이지 이탈률 증가
- 결제 취소율 증가
- 고객센터 문의 증가
- 장기 리텐션 악화
그래서 primary metric 과 함께 guardrail metric 을 미리 정해두는 것이 중요하다.
여기서 primary metric 은 이 실험이 성공했는지 가장 먼저 판단하는 핵심 지표다.
예를 들어 CTA 버튼 문구를 바꾸는 실험이라면 클릭률, 결제 전환율 같은 지표가 primary metric 이 될 수 있다.
반면 guardrail metric 은 primary metric 을 올리는 대신 다른 중요한 지표를 망치고 있지 않은지 보는 안전장치 지표다.
예를 들어 클릭률은 올랐지만 이탈률, 결제 취소율, 고객센터 문의율, 장기 리텐션 이 악화된다면 실험 결과를 다시 봐야 한다.
조직의 의사결정을 데이터 기반으로 한다.
실험이 있으면 논의가 데이터 중심으로 이동한다.
- 어떤 가설을 세웠는가
- 어떤 사용자에게 노출했는가
- 결과가 얼마나 컸는가
- 불확실성은 어느 정도인가
를 기준으로 이야기하게 된다.
2. A/B Test 에서 2개의 그룹으로 정확히 분배하기 위한 방법
먼저 정확히 의 의미부터 정리해보면
실무에서 흔히 50:50으로 정확히 나눠야 한다 고 말하지만, 이 말은 두 가지 의미로 나뉜다.
- 같은 사용자는 언제 들어와도 같은 그룹이어야 한다
- 전체적으로 편향 없이 거의 50:50 에 가깝게 나뉘어야 한다
이 두 가지는 A/B Test 의 핵심이다.
새로운 사용자가 진입했을 때 50:50으로 분배하는 방법
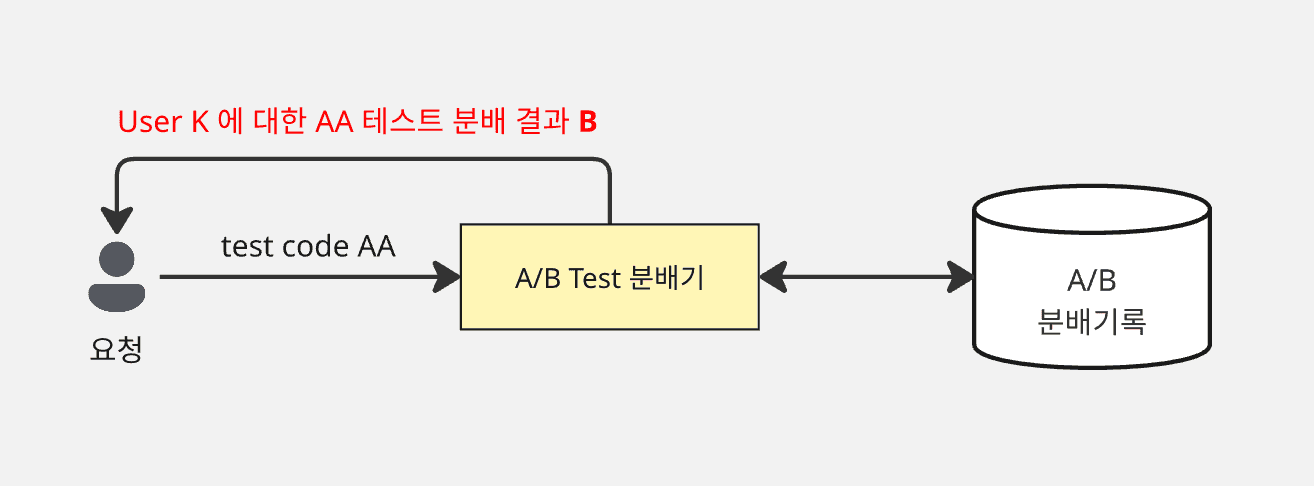
위 그림과 같이 매 순간 사용자 수가 완벽하게 exact 50:50 인 상태를 강제하는 것은 분산 시스템에서는 비용이 매우 크다.
그래서 대부분의 서비스는 stable assignment + unbiased split 을 목표로 한다.
가장 추천하는 방식은 아래와 같다.
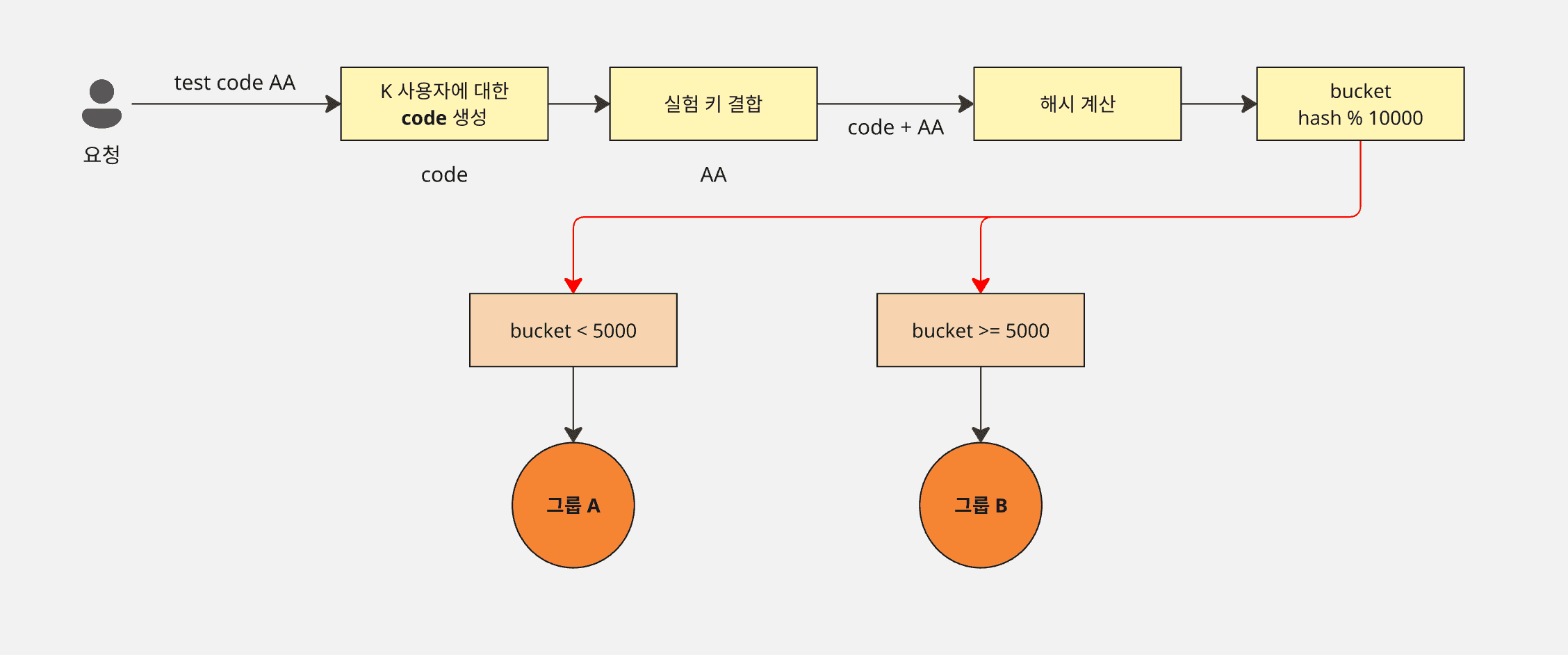
- 먼저 실험의 단위가 되는
unit(예시에서는 user) 을 정한다. - 로그인 사용자는
user_id, 비로그인 사용자는anonymous_id(cookie)를 만들어서 사용한다 (반드시 변하지 않아야 한다). experiment_key + unit_id를 합친 문자열로 stable hash 를 만든다.- hash 값을 정수로 바꾼 뒤
bucket = hash % 10000을 계산한다. bucket < 5000이면 A, 아니면 B 로 배정한다.- 최초 노출 시 assignment 를 저장하고, exposure event 를 한 번만 적재한다.
이 방식의 장점은 명확하다.
- 같은 사용자는 항상 같은 그룹으로 들어간다
- 서버가 여러 대여도 동일한 결과가 나온다
- 캐시와 로그를 다루기 쉽다
- 실험 키만 바꾸면 새 실험을 시작할 수 있다
구현 예시
아래는 이해를 위한 간단한 TypeScript 예시이다.
import { createHash } from 'crypto';
type Variant = 'A' | 'B';
function assignVariant(experimentKey: string, unitId: string): Variant {
const input = `${experimentKey}:${unitId}`;
const hash = createHash('sha256').update(input).digest('hex').slice(0, 8);
const bucket = parseInt(hash, 16) % 10000;
return bucket < 5000 ? 'A' : 'B';
}정말 exact 50:50 이 필요하면
(위 hash 방식은 약 49:51 로 분배된다) 만약 금융, 가격정책, 오퍼 발급량처럼 그룹 수를 아주 엄격하게 맞춰야 하는 경우라면 중앙 상태를 둔 방식도 사용할 수 있다.
예를 들면 다음과 같다.
- Redis
INCR로 카운터를 증가시키고 짝수/홀수로 배정 - 미리 섞어 둔 assignment queue 를 하나씩 꺼내 사용
이 방식은 순간적으로도 exact count 를 맞추기 쉽다.
하지만 단점도 분명하다.
- 중앙 저장소에 강하게 의존한다
- 장애 시 배정 로직이 같이 흔들린다
- 재시도, 중복 요청, 타임아웃 처리 로직이 복잡해진다
그래서 일반적인 제품 실험에서는 deterministic hash 가 더 실용적이다.
해시를 쓰면 100명이 들어왔을 때 90:10 이 될 수도 있지 않을까
이론적으로는 가능하다.
해시 기반 분배는 항상 exact 50:50 을 강제하는 방식이 아니라, 각 사용자를 50% 확률 로 한쪽 bucket 에 넣는 방식에 가깝다.
즉, 중요한 것은 아래 두 가지이다.
- 각 사용자가 편향 없이 배정되는가
- 같은 사용자가 다시 들어와도 같은 그룹으로 유지되는가
그래서 작은 표본에서는 60:40, 55:45 처럼 보이는 현상이 충분히 나올 수 있다.
100명을 예로 들면 기대값은 50:50 이고, 표준편차는 다음과 같다.
sqrt(n * p * (1 - p))
= sqrt(100 * 0.5 * 0.5)
= 5즉, 100명 수준에서는 대략 50 ± 10 정도 범위는 꽤 자연스럽다.
- 60명 vs 40명 이상 차이가 날 확률은 양쪽 합쳐 약
5.7% - 55명 vs 45명 이상 차이가 날 확률은 양쪽 합쳐 약
36.8%
반면 90:10 은 가능은 하지만 사실상 거의 나오지 않는다.
- 100명 중 한쪽이 90명 이상일 확률은 양쪽 합쳐 약
0.00000000000000003
그럼 hash 기반에서 exact 50:50 이 되려면 최소 몇 명이 필요할까
여기서 헷갈리기 쉬운 포인트가 하나 있다.
bucket 공간 은 이미 exact 50:50 으로 나뉘어 있다.
0 ~ 4999는 A5000 ~ 9999는 B
즉, hash % 10000 기준으로 보면 10000개의 bucket 중 정확히 절반 5000개가 A 이고, 절반 5000개가 B 이다.
하지만 실제 유입 사용자 표본 이 exact 50:50 이 되는 것은 전혀 다른 문제다.
이 기준에서는 보장되는 최소 표본 수 가 없다.
이유는 간단하다.
- 표본 수가 홀수면 exact 50:50 자체가 불가능하다
- 표본 수가 짝수여도 exact 50:50 은 가능할 뿐 보장되지는 않는다
예를 들어 최소로 가능한 짝수 표본은 2명 이다.
하지만 이 경우에도 결과는 1:1 이거나, 한쪽으로 몰린 2:0 이다.
즉, 가능한 최소 표본 수 는 2 이지만, 정확히 반반이 되도록 보장하는 최소 표본 수 는 존재하지 않는다.
좋은 해시가 입력을 bucket 공간에 균등하게 퍼뜨린다고 가정하면, 표본 수가 n 명일 때 exact 50:50 이 나올 확률은 다음과 같다.
P(exact 50:50) = C(n, n / 2) / 2^n (n 이 짝수일 때)
P(exact 50:50) = 0 (n 이 홀수일 때)예를 들면 다음과 같다.
n = 2이면 exact 50:50 확률은50%n = 10이면 exact 50:50 확률은 약24.6%n = 100이면 exact 50:50 확률은 약7.96%
즉, 표본이 커진다고 해서 exact 50:50 자체가 더 잘 보장되는 것은 아니다.
커질수록 좋아지는 것은 정확히 반반일 확률 이 아니라 비율 오차의 상대적 크기 다.
그래서 실무에서는 보통 이렇게 이해하면 된다.
hash 방식: exact count 는 아니지만 장기적으로 50:50 에 수렴하고, 운영이 단순하다counter 방식: 순간적인 exact count 까지 맞출 수 있지만 중앙 상태 관리 비용이 커진다
트래픽이 충분히 커지면 hash 방식의 실제 분배 비율은 점점 50:50 에 가까워진다.
TypeScript 로 10만 사용자 분배를 확인해보기
위 설명을 코드로 확인하고 싶다면, 10만 명 의 가상 사용자 ID 를 만든 뒤 실제로 hash assignment 를 돌려보면 된다.
여기서 테스트의 목적은 항상 50,000 대 50,000 이 나오는지 확인하는 것이 아니다.
목적은 충분히 큰 표본에서 결과가 50:50 에 매우 가깝게 나오는지 확인하는 데 있다.
아래 예시는 Node.js 환경에서 바로 실행할 수 있는 TypeScript 코드다.
import { strict as assert } from 'node:assert';
import { createHash } from 'node:crypto';
type Variant = 'A' | 'B';
const TOTAL_USERS = 100_000;
const EXPERIMENT_KEY = 'checkout-button-color-v1';
const MAX_RATIO_GAP = 0.01;
function assignVariant(experimentKey: string, unitId: string): Variant {
const input = `${experimentKey}:${unitId}`;
const hash = createHash('sha256').update(input).digest('hex').slice(0, 8);
const bucket = parseInt(hash, 16) % 10_000;
return bucket < 5_000 ? 'A' : 'B';
}
function runDistributionTest(totalUsers: number) {
let groupA = 0;
let groupB = 0;
for (let index = 0; index < totalUsers; index += 1) {
const unitId = `user-${index}`;
const variant = assignVariant(EXPERIMENT_KEY, unitId);
if (variant === 'A') {
groupA += 1;
continue;
}
groupB += 1;
}
const ratioA = groupA / totalUsers;
const ratioB = groupB / totalUsers;
const ratioGap = Math.abs(ratioA - ratioB);
console.table({
totalUsers,
groupA,
groupB,
ratioA: ratioA.toFixed(4),
ratioB: ratioB.toFixed(4),
ratioGap: ratioGap.toFixed(4),
});
assert.equal(groupA + groupB, totalUsers);
assert.ok(
ratioGap < MAX_RATIO_GAP,
`A/B ratio gap is too large: ${(ratioGap * 100).toFixed(2)}%p`,
);
}
runDistributionTest(TOTAL_USERS);여기서 MAX_RATIO_GAP = 0.01 은 A 비율과 B 비율의 차이가 1%p 미만이면 통과 라는 뜻이다.
예를 들어 위 코드에서 experiment_key = checkout-button-color-v1 이고, 사용자를 user-0 부터 user-99999 까지 넣어보면 아래처럼 나온다.
A = 49,971B = 50,029- 비율 차이 =
0.058%p
예를 들어 아래 둘은 모두 통과다.
50,120 vs 49,88050,420 vs 49,580
반대로 51,000 vs 49,000 이면 비율 차이가 2.0%p 이므로 실패한다.
즉, 이 테스트는 exact 50:50 검증이 아니라 대규모 표본에서 실무적으로 충분히 균등한가 를 보는 테스트다.
여기서 한 가지 더 분명히 해야 한다.
% 10000 이 50:50 을 보장하는 것이 아니다.
보장을 만드는 것은 좋은 해시 함수가 입력값을 bucket 공간에 거의 균일하게 퍼뜨린다 는 성질이다.
예를 들어 hash % 10000 을 하면 결과는 0 ~ 9999 중 하나가 된다.
그리고 아래처럼 자르면 된다.
0 ~ 4999는 A5000 ~ 9999는 B
즉, 10000개의 bucket 중 절반 5000개가 A, 절반 5000개가 B 이기 때문에 각 사용자 는 거의 50% 확률로 A 또는 B 에 들어간다고 볼 수 있다.
하지만 이건 어디까지나 확률적으로 공정하다 는 뜻이지, 어떤 작은 표본에서도 정확히 반반이 된다는 뜻은 아니다.
예를 들어 100명의 사용자가 모두 9000 이상 bucket 을 받는 것도 이론적으로는 가능하다.
다만 그 확률은 다음과 같다.
(1000 / 10000) ^ 100
= 0.1 ^ 100즉, 사실상 거의 일어나지 않는다.
반대로 말하면 해시 기반 분배의 본질은 다음과 같다.
same input -> same bucket은 강하게 보장한다many inputs -> almost uniform distribution은 좋은 해시의 성질에 기대한다exact count 50:50은 보장하지 않는다
만약 어떤 시점의 100명도 무조건 50:50 이어야 한다면, 그건 해시의 문제가 아니라 stateful balancing 이 필요한 요구사항이다.
3. 데이터의 분석 방법
실험이 끝나면 많은 팀이 곧바로 B 가 더 높네 라고 결론부터 내린다.
하지만 그 전에 확인해야 할 것이 있다.
SRM 부터 확인한다
SRM(Sample Ratio Mismatch) 은 기대한 분배와 실제 분배가 유의미하게 다르게 나오는 상황을 말한다.
예를 들어 50:50 실험인데 실제 노출은 57:43 이 나왔다면, 먼저 의심해야 할 것은 기능 성능이 아니라 배정 또는 로깅 문제다.
대표적인 원인은 아래와 같다.
- 한쪽 variant 에서 exposure 이벤트가 덜 찍힘
- 특정 브라우저/디바이스에서 실험 코드가 실행되지 않음
- 로그인 전/후 식별자가 깨짐
- 캐시 또는 CDN 이 한쪽 결과만 더 많이 노출함
SRM 을 통과하지 못한 실험은 통계 기법을 바꿔도 해석이 흔들린다.
예시 데이터를 하나 두고 보자
아래 예시로 설명해보겠다.
- A: 10,000명 노출, 900명 전환, 전환율 9.0%
- B: 10,000명 노출, 1,020명 전환, 전환율 10.2%
- 차이:
+1.2%p - 상대 개선:
+13.3%

분석 전에 가설과 종료 조건을 먼저 적어둔다
실무에서는 통계 기법을 고르기 전에 아래 네 가지를 먼저 문장으로 적어두는 편이 좋다.
귀무가설(H0): A 와 B 의 차이가 없거나, B 가 더 낫지 않다대립가설(H1): B 가 A 보다 낫거나, 최소한 둘 사이에 차이가 있다최소로 의미 있는 효과(MDE): 어느 정도 차이부터 사업적으로 의미 있다고 볼지종료 조건: 얼마의 표본을 모을지, 언제 결과를 읽을지
이걸 미리 정해두지 않으면 실험이 끝난 뒤 결과에 맞춰 해석을 바꾸기 쉽다.
특히 통계적으로 차이가 있다 와 출시할 만큼 가치가 있다 는 다른 질문이다.
예를 들어 전환율이 +0.1%p 올랐고 p-value 도 통과했다고 하자.
트래픽이 아주 큰 서비스라면 의미가 있을 수 있지만, 구현 복잡도나 운영 비용이 더 크다면 제품 결정은 달라질 수 있다.
Frequentist 방식 (빈도주의)
가장 전통적인 방법이다.
보통 전환율 실험에서는 two-proportion z-test 나 chi-square test 를 사용한다.
핵심은 먼저 차이가 없다 는 귀무가설을 세우고, 지금 관측된 차이가 그 가정 아래에서 얼마나 드문지를 보는 것이다.
위 예시에서는 대략 다음처럼 읽을 수 있다.
- p-value 는 약
0.004 - 95% confidence interval 은 약
+0.38%p ~ +2.02%p
이 결과를 실무적으로 해석하면 다음과 같다.
유의수준(alpha) = 0.05를 미리 정해두었다면, p-value 가 그보다 작으므로 귀무가설을 기각할 수 있다- 즉
실제로 차이가 전혀 없는데 지금 같은 결과가 나올 가능성이 충분히 낮다고 본다 - confidence interval 이
0을 포함하지 않고 플러스 구간에 있으므로, 효과 방향도 B 쪽으로 읽을 수 있다
Frequentist 의 장점은 명확하다.
- 팀에 익숙한 경우가 많다
- 의사결정 기준을 표준화하기 쉽다
- A/A test, 다중 비교, 검정력 분석 같은 체계와 잘 연결된다
다만 자주 놓치는 포인트도 있다.
- p-value 는
B 가 더 좋을 확률이 아니다 유의하지 않음은효과 없음과 같은 말이 아니다- 중간 결과를 계속 보다가 유리할 때 멈추면 false positive 확률이 커진다
- 통계적 유의성과 사업적 유의성은 다르다
여기서 같이 알아야 하는 개념이 1종 오류, 2종 오류, 검정력(power) 이다.
1종 오류(false positive): 실제로 효과가 없는데 있다고 판단하는 경우2종 오류(false negative): 실제로 효과가 있는데 놓치는 경우유의수준(alpha): 1종 오류를 어느 정도까지 감수할지 정하는 기준검정력(power): 실제 효과가 있을 때 그 차이를 잡아낼 확률
그래서 표본 수가 너무 적으면, 의미 있는 변화가 있어도 유의하지 않음 으로 끝날 수 있다.
실무에서 실험 실패 로 보이는 것 중 일부는 사실 검정력 부족 인 경우가 많다.
보통은 실험 전에 아래 값을 먼저 정하고 필요한 표본 수를 계산한다.
- 기준 전환율
- 최소로 감지하고 싶은 변화량(MDE)
- 유의수준(alpha)
- 목표 검정력(보통
80%또는90%)
즉, Frequentist 는 우연으로 보기 어려운가 를 판단하는 데 강하지만, 그 판단이 믿을 만하려면 처음부터 설계가 잘 되어 있어야 한다.
그래서 실무에서는 p-value 하나 보다 아래 세 가지를 함께 보는 편이 좋다.
- effect size
- confidence interval
- guardrail metric 변화
Bayesian 방식 (베이지안)
Bayesian 은 질문 자체를 좀 더 비즈니스 친화적으로 바꿔준다.
Frequentist 가 귀무가설 하에서 이런 데이터가 나올 확률이 얼마나 낮은가 를 묻는다면,
Bayesian 은 지금 데이터와 prior(사전 가정) 를 바탕으로 B 가 A 보다 좋을 확률이 얼마나 되는가 를 묻는다.
베이지안 해석은 보통 아래 세 가지로 생각하면 정리가 쉽다.
prior: 실험 전에 갖고 있던 가정이나 과거 지식likelihood: 이번 실험에서 실제로 관측된 데이터posterior: 둘을 합쳐 업데이트한 최종 확률
위 예시를 단순한 Beta prior 로 보면 대략 다음처럼 읽을 수 있다.
P(B > A) ≈ 99.8%- 95% credible interval 은 약
+0.38%p ~ +2.02%p - expected loss 는 거의 0에 가깝다
이 방식이 좋은 이유는 설명이 직관적이기 때문이다.
- PM 에게는
B 가 이길 확률 - 비즈니스 팀에는
출시했을 때 기대 손실 - 운영 팀에는
의사결정 임계값
으로 연결하기 쉽다.
또한 prior 를 쓸 수 있다는 점도 차이점이다.
예를 들어 비슷한 CTA 개선 실험이 과거에 계속 플러스 효과를 냈다면, 그런 정보를 약한 prior 로 반영할 수 있다.
물론 데이터가 충분히 쌓이면 prior 의 영향은 점점 작아지고, 실제 관측 데이터가 더 큰 비중을 갖게 된다.
다만 Bayesian 도 만능은 아니다.
- prior 를 어떻게 두는지 합의가 필요하다
- 팀이 익숙하지 않으면 결과를 오히려 더 어렵게 느낄 수 있다
- 여러 실험이 동시에 돌아갈 때 운영 기준을 문서화해야 한다
- 중간에 계속 결과를 보더라도
어느 확률에서 출시할지,expected loss 를 얼마나 허용할지같은 기준은 미리 정해두는 편이 좋다
즉, Bayesian 은 어느 안이 더 좋을 가능성이 큰가, 지금 결정했을 때 평균적으로 얼마나 아쉬울 수 있는가 를 바로 말해주기 때문에 제품 의사결정 언어와 잘 맞는다.
Frequentist 와 Bayesian 중 무엇이 더 좋은가
정답은 팀의 운영 방식에 따라 다르다 이다.
둘은 사실 경쟁 관계라기보다 서로 다른 질문에 답하는 도구 에 가깝다.
아래처럼 생각하면 편하다.
- 표준화된 실험 문화, 명확한 유의수준, 사전 샘플 수 계산이 중요하면 Frequentist
- 확률 문장, expected loss, 유연한 의사결정 흐름이 중요하면 Bayesian
- 트래픽이 작아서
유의하지 않음이 자주 나오는 팀이라면 Bayesian 리포트가 더 실무적으로 느껴질 수 있다
실무에서는 둘 중 하나만 고집하기보다,
- 표준 리포트는 Frequentist 로 만들고
- 최종 제품 의사결정 메모에는 Bayesian 해석을 덧붙이는
식으로 함께 쓰는 경우도 많다.
정리
A/B Test 는 통계 문제가 아니라 제품 의사결정 시스템 에 더 가깝다.
좋은 실험은 보통 아래 순서로 만들어진다.
- 왜 실험하는지 명확한 가설을 세운다
- 사용자를 안정적으로 배정한다
- exposure 와 conversion 로그를 정확히 남긴다
- SRM 을 먼저 확인한다
- Frequentist, Bayesian, 또는 더 적합한 대안으로 해석한다
개인적으로는 2번과 3번이 특히 중요하다고 생각한다.
배정이 흔들리거나 로그 품질이 나쁘면, 그 다음의 통계는 아무리 정교해도 믿기 어렵기 때문이다.
결국 A/B Test 의 품질은 분석 공식보다 실험 설계와 데이터 수집 품질 에서 먼저 결정된다.