이 글은 Kief Morris가 2026년 3월 4일에 작성한 Humans and Agents in Software Engineering Loops를 읽고, 핵심 논지를 한국어로 풀어쓴 해설형 번역 글입니다. 원문 전체를 직역하기보다, 실제 팀 개발에 적용할 수 있는 문맥과 해석을 함께 정리했습니다.
왜 이 글이 중요할까
최근 AI 코딩 도구를 둘러싼 논의는 보통 두 극단으로 흐릅니다.
- 그냥 에이전트에게 맡기고 결과만 받으면 된다는 입장
- 사람이 끝까지 붙어서 생성된 코드를 한 줄씩 검수해야 한다는 입장
이 글은 그 둘 사이에서 더 실용적인 자리를 제안합니다.
핵심 질문은 AI가 코드를 잘 쓰는가가 아니라, 아이디어를 결과로 바꾸는 루프를 누가 설계하고 운영하는가 입니다.
1. why loop 와 how loop
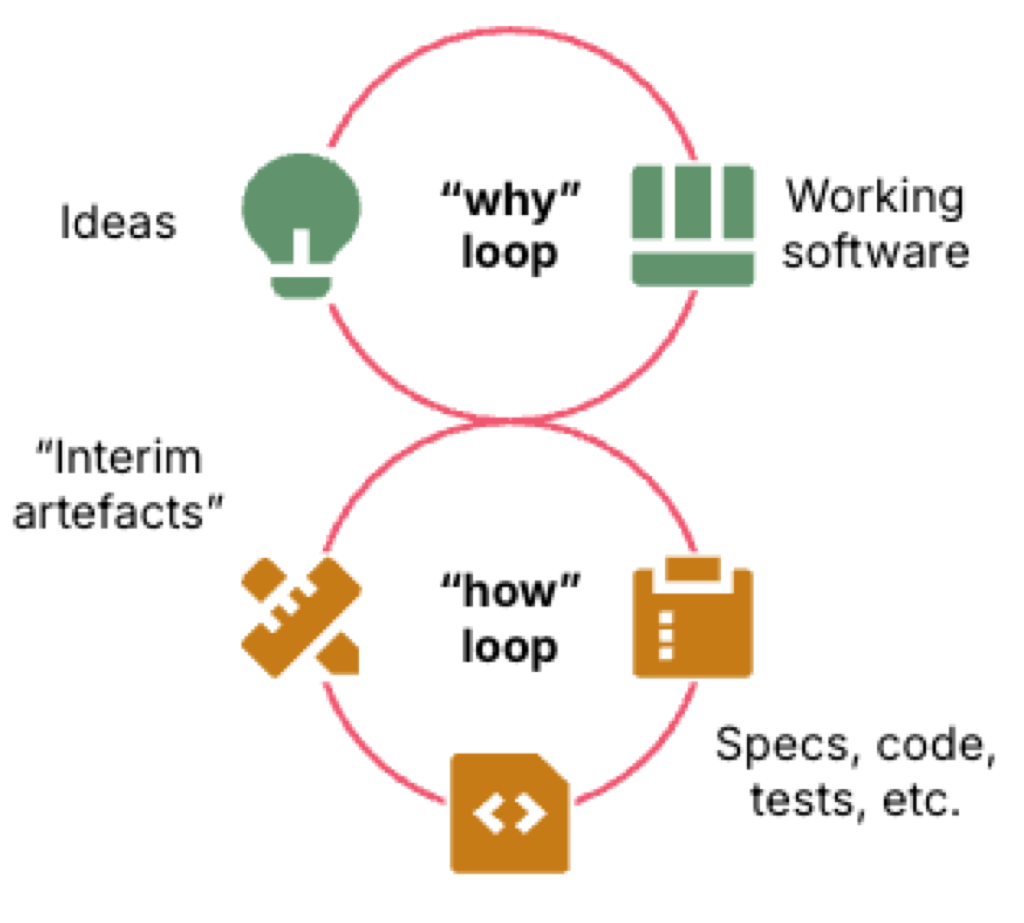
저자는 소프트웨어 개발을 크게 두 개의 루프로 봅니다.
- why loop: 아이디어를 실제 동작하는 소프트웨어로 바꾸고, 그 결과를 보고 다시 방향을 수정하는 루프
- how loop: 그 결과를 만들기 위해 명세, 코드, 테스트, 인프라, 문서 같은 중간 산출물을 만들어 가는 루프
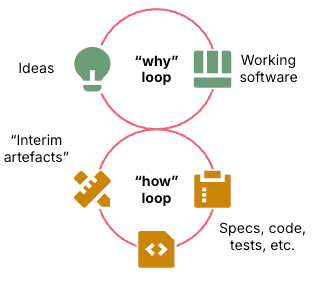
여기서 중요한 포인트는 코드, 테스트, 설계 문서가 목표 그 자체가 아니라는 점입니다.
이것들은 모두 결과물을 만들기 위한 중간 수단입니다.
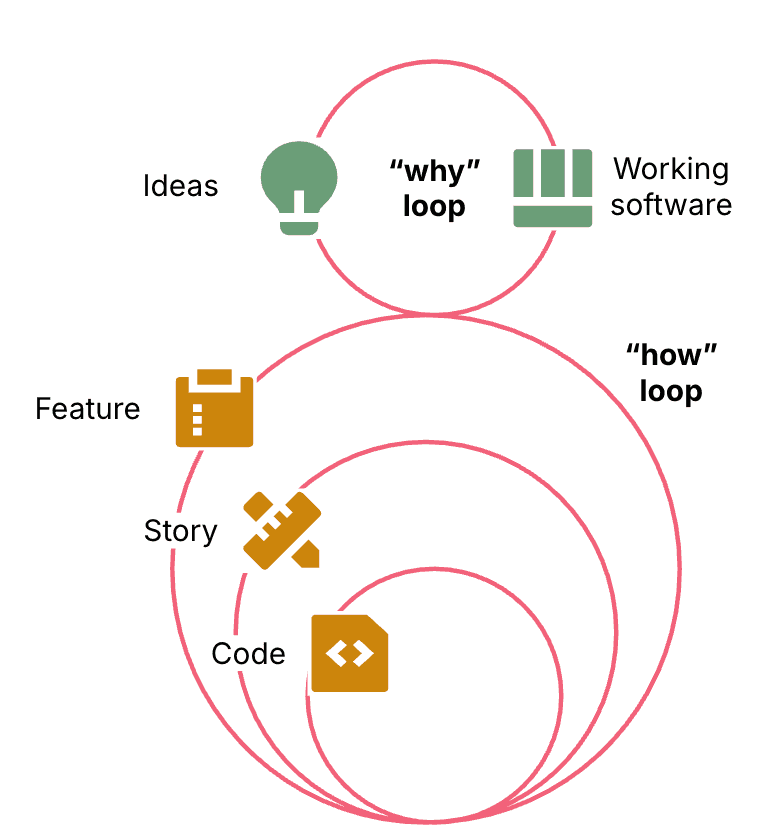
또 how loop 는 한 겹이 아닙니다.
기능 단위의 루프가 있고, 그 안에 스토리 단위 루프가 있고, 더 안쪽에는 실제 코드와 테스트를 돌리는 작은 루프가 있습니다.
즉, 에이전트를 잘 쓴다는 것은 “한 번에 코드 생성”보다 “여러 단계의 루프를 어떻게 잘게 나누고 연결하느냐”에 더 가깝습니다.
2. 인간을 루프 밖에 둘 때
저자가 말하는 humans outside the loop 는 사람이 why loop 만 담당하고, 구현을 위한 how loop 는 대부분 에이전트에게 맡기는 방식입니다.
흔히 말하는 바이브 코딩이나, 일부 스펙 주도 개발 방식이 여기에 가깝습니다.
이 방식이 매력적인 이유는 분명합니다.
사람은 결과만 설명하고, 에이전트는 알아서 코드를 만들고 수정합니다.
당장 눈앞의 생산성만 보면 가장 빠른 방식처럼 보입니다.
하지만 글은 여기서 중요한 반론을 던집니다. 내부 품질 은 여전히 중요하다는 것입니다.
왜 그럴까요?
- 시스템은 기능적으로 맞기만 하면 끝나지 않습니다.
- 성능, 안정성, 보안, 운영 비용, 규제 준수 같은
외부 품질도 함께 만족해야 합니다. - 구조가 지나치게 엉켜 있으면 에이전트 역시 코드를 더 느리게 이해하고, 더 자주 헤매며, 더 많은 비용을 씁니다.
즉, “어차피 AI가 읽을 코드니까 깨끗하지 않아도 된다”는 생각은 현실에서는 잘 성립하지 않습니다.
정리된 코드베이스는 사람뿐 아니라 에이전트에게도 더 빠른 작업 환경입니다.
3. 인간을 루프 안에 둘 때
반대로 humans in the loop 는 사람이 구현 루프의 한가운데에 서서, 에이전트가 만든 산출물을 계속 확인하고 수정하는 방식입니다.
이 접근이 완전히 틀렸다는 뜻은 아닙니다. 실제로 에이전트가 이상한 방향으로 반복하다가 시간을 쓰는 문제는 자주 발생하고, 숙련된 개발자가 보면 몇 초 만에 고칠 수 있는 경우도 많습니다.
문제는 사람이 병목이 된다는 점입니다.
- 에이전트는 매우 빠르게 코드를 만듭니다.
- 사람은 그 속도로 매번 명세를 보강하고, 결과를 검토하고, 한 줄씩 승인할 수 없습니다.
- 결국 “AI 덕분에 빨라졌다”기보다 “검수 비용이 더 늘었다”는 상황이 생깁니다.
여기서 글은 shift left 를 이야기합니다.
사람이 뒤에서 결과물을 계속 검사하기보다, 에이전트가 처음부터 더 나은 결과를 내도록 기준과 검증 방식을 앞단에 심어야 한다는 뜻입니다.
4. 인간은 루프 위에 있어야 한다
이 글의 핵심은 바로 humans on the loop 입니다.
사람은 산출물 하나하나를 직접 고치는 역할보다, 에이전트가 일하는 루프 자체를 설계하고 관리하는 역할로 올라가야 한다는 주장입니다.
저자가 말하는 harness 는 단순한 프롬프트 묶음이 아닙니다.
에이전트가 좋은 결과를 내도록 잡아 주는 레일 전체에 가깝습니다.
실무로 옮기면 이런 것들이 harness 에 포함될 수 있습니다.
- 요구사항을 쓰는 형식과 템플릿
- 작업을 쪼개는 규칙
- 코드 스타일과 아키텍처 가드레일
- 테스트, 린트, 타입체크, 보안 스캔
- 배포 조건과 롤백 기준
- 결과를 평가하는 체크리스트나 자동화된
eval
이 관점이 좋은 이유는, 결과가 마음에 들지 않을 때의 대응 방식이 달라지기 때문입니다.
in the loop: 지금 나온 산출물을 직접 고칩니다.on the loop: 왜 이런 산출물이 나왔는지 보고, 다음부터 더 잘 나오도록 하네스를 바꿉니다.
즉, 일회성 수정보다 재현 가능한 개선 에 집중하게 됩니다.
5. agentic flywheel 이라는 다음 단계
여기서 한 단계 더 나아가면, 사람만 하네스를 개선하는 것이 아니라 에이전트가 하네스 개선안까지 제안하게 됩니다.
이것이 글에서 말하는 agentic flywheel 입니다.
이 루프를 강하게 만드는 신호는 생각보다 다양합니다.
- 테스트와 자동 평가 결과
- CI/CD 파이프라인 단계별 실패 원인
- 성능 측정 결과와 장애 재현 시나리오
- 운영 로그와 사용자 여정 데이터
- 실제 비즈니스 결과
이 신호가 충분히 쌓이면, 에이전트는 단순히 “코드 작성기”가 아니라 “워크플로 개선 제안자”가 됩니다.
처음에는 사람이 제안을 검토하고, 익숙해지면 위험이 낮은 항목부터 자동 반영하도록 범위를 넓힐 수 있습니다.
결국 충분히 성숙한 영역에서는 다시 humans outside the loop 처럼 보일 수도 있습니다.
하지만 그 상태는 무작정 맡긴 결과가 아니라, 잘 설계된 루프가 안정화된 결과라는 점이 다릅니다.
읽고 나서 든 생각
이 글이 좋았던 이유는 “AI가 개발자를 대체하는가” 같은 익숙한 질문을 다른 차원으로 옮겨 주기 때문입니다.
앞으로 개발자가 해야 할 일은 줄어들기보다 오히려 더 선명해진 것 같습니다.
- 무엇을 만들지 결정하는 일
- 어떤 기준으로 좋은 결과를 판정할지 정의하는 일
- 에이전트가 헤매지 않도록 작업 흐름을 설계하는 일
- 생산성, 품질, 운영 안정성을 모두 연결하는 피드백 루프를 만드는 일
예전에는 개발자가 직접 구현을 담당했다면, 이제는 루프 설계자, 평가 기준 설계자, 하네스 운영자 의 비중이 더 커지는 것 같아요.
특히 팀 단위로 AI를 도입할수록 차이는 더 커질 것 같습니다.
개인이 프롬프트를 잘 쓰는 것보다, 팀이 공통 하네스를 잘 만드는 쪽이 훨씬 더 큰 생산성 차이를 만들 가능성이 높습니다.
마무리
원문이 말하는 핵심을 한 문장으로 줄이면 이렇습니다.
사람은 코드를 모두 직접 쓰는 존재에서 사라지는 것이 아니라 에이전트가 올바르게 일하도록 루프를 설계하는 존재 로 이동하고 있습니다.
바이브 코딩이든, PR 리뷰 자동화든, 테스트 생성이든 결국 중요한 것은 도구 하나가 아니라 루프 전체입니다.
AI 시대에 강한 팀은 더 좋은 모델을 먼저 쓰는 팀보다, 더 좋은 harness 와 더 좋은 피드백 구조를 먼저 갖춘 팀일 가능성이 높습니다.